


CRC الگوریتمی است که برای تشخیص خطاها در انتقال داده ها استفاده میشود. الگوریتم CRC یک checksum تولید میکند که یک مقدار ثابت است که از دادههای ارسال شده به دست میآید. سپس این checksum به دادهها اضافه و همراه با آن ارسال میشود. پس از دریافت دادهها، گیرنده همان الگوریتم CRC را انجام میدهد و checksum محاسبه شده را با نمونه دریافتی مقایسه میکند. اگر مطابقت داشته باشند، نشان میدهد که دیتا به درستی منتقل شده و در غیر این صورت، خطایی در زمان انتقال رخ داده است.
Cyclic Redundancy Checks یک روش اعتبارسنجی است که از فرمولهای ریاضی برای ایجاد یک مقدار منحصر به فرد برای بلوکهای دادهای که ارسال میشود، استفاده میکند. این مقدار که checksum نامیده میشود، در حین انتقال به عنوان مرجع برای گیرنده به دادهها اضافه میشود.
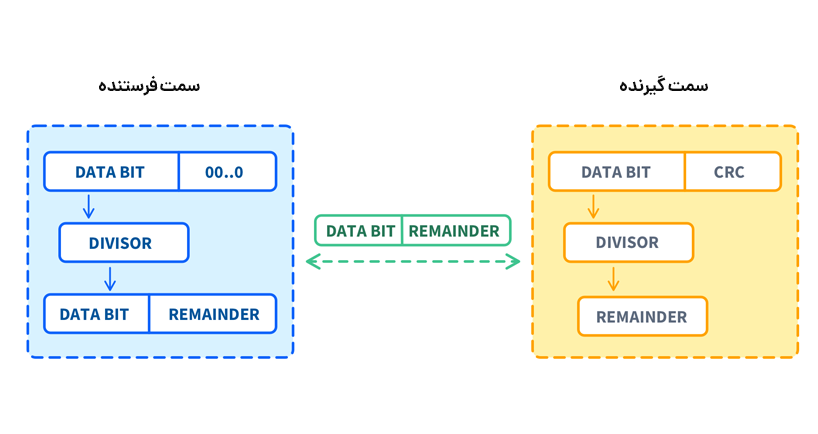
سپس گیرنده یک checksum را با دادههای دریافتی خود محاسبه و تایید میکند که آیا این دو مقدار مطابقت دارند یا خیر. اگر دو مقدار مطابقت داشته باشند، دادهها به درستی منتقل شدهاند و اگر مقادیر مطابقت نداشته باشند، دادهها هم به درستی انتقال داده نشدهاند.
همچنین در سیستمهای ذخیرهسازی دادهها، از جمله هارد دیسکها و حافظه فلش، برای تایید صحت دادههای ذخیرهشده استفاده میشود. CRC در پروتکلهایی مانند Modbus، controller area network (CAN) و بسیاری دیگر که انتقال داده قابل اعتماد ضروری است، بسیار مهم است.
CRC چگونه کار میکند؟
CRC بر اساس برخورد با دادههایی است که قرار است به عنوان یک چند جملهای منتقل شوند. فرستنده و گیرنده بر روی یک چند جملهای مقسوم علیه ثابت توافق میکنند که اغلب به آن چند جملهای مولد می گویند. دادهها با یک checksum افزوده میشوند، که باقیمانده تقسیم چند جملهای داده های اصلی توسط چند جملهای مولد است. در انتهای فرستنده، چکسام CRC محاسبه شده و قبل از ارسال به دادهها اضافه میشود. در انتهای گیرنده، داده های دریافتی به همراه checksum با چند جملهای مولد یکسان تقسیم می شود. اگر باقیمانده صفر باشد، داده ها بدون خطا در نظر گرفته میشوند. در غیر این صورت، خطا تشخیص داده میشود.
استفاده از چند جملهای های CRC و کدهای چرخهای ممکن است پیچیده به نظر برسد، اما این مفهوم ساده تر از آن چیزی است که به نظر می رسد. این چند جملهایها، نمایشهای ریاضی هستند که به فرآیند تشخیص خطا کمک میکنند. کدهای چرخهای، در زمینه CRC، به کدهایی اطلاق میشوند که در آن جابهجایی چرخهای هر کلمه رمز معتبر منجر به کلمه رمز معتبر دیگری میشود.
برای درک بهتر، یک مثال ساده از تصحیح خطا با استفاده از یک جمعبندی اولیه را در نظر بگیرید. تصور کنید که یک عدد باینری ارسال و یک بیت اضافی بیافزایید که نشان دهنده برابری یا مجموع بیتهای اصلی است. اگر داده های دریافتی با برابری مورد انتظار مطابقت نداشته باشد، یک خطا شناسایی می شود.
CRC نسخه پیچیده تری از این فرآیند است. به جای یک مجموع ساده، چند جمله ای CRC محاسبات پیچیده تری را انجام می دهد و افزونگی بیشتری را معرفی می کند و قابلیت تشخیص خطا را افزایش می دهد. این پیچیدگی افزایش یافته برای مدیریت خطاهای ظریف تر و ارائه مکانیسم بررسی خطای قوی تر بسیار مهم است.
آشنایی با الگوریتم های CRC
چکهای افزونگی چرخهای، در هسته خود، محاسبات ریاضی هستند. الگوریتم های Cyclic Redundancy Check متفاوتی وجود دارد که هر کدام مزایا و معایب خود را دارند. انواع اصلی الگوریتمهای بررسی افزونگی چرخه ای که در مورد آنها بحث خواهیم کرد عبارتند از CRC-8، CRC-16 و CRC-32.
یکی از مفاهیم کلیدی برای درک الگوریتمهای بررسی افزونگی چرخهای این است که هر چه الگوریتم کمتر باشد، احتمال برخورد دادهها بیشتر میشود. این بدان معناست که استفاده از CRC-8 منجر به درصد بالاتری از برخورد دادهها (data collision) در طول زمان نسبت به آنچه ممکن است با استفاده از CRC-16 یا CRC-32 تجربه شود، میشود.
برخورد دادهها زمانی اتفاق میافتد که دو بلوک منحصربهفرد از دادهها، مقدار checksum یکسانی را تولید کنند. یک مثال سادهشده این است که شما یک مقدار منحصر به فرد را به جعبههای منحصربهفرد اختصاص دهید. اگر فقط از اعداد ۰ تا ۹ استفاده کردهاید، کادر یازدهم چاره ای جز مطابقت با مقداری که قبلا به کادر دیگری اختصاص داده شده است، نخواهد داشت، حتی اگر کادرها منحصر به فرد باشند. اگر مجموعه مقادیر خود را بین ۰ تا ۹۹ افزایش دهید، می توانید ۱۰۰ مقدار منحصر به فرد را قبل از خطر برخورد داده ها اختصاص دهید.
حالا بیایید همه چیز را پیچیده کنیم. به جای تخصیص مقادیر، با جمع کردن اعداد با یکدیگر، مقادیر را محاسبه می کنید. به همه راه هایی فکر کنید که می توانید اعداد ۰-۹ را برای رسیدن به مقدار ۱۳ اضافه کنید.
بیایید دوباره مقادیر احتمالی خود را به ۰-۹۹ افزایش دهیم. به چند روش می توانیم اعداد بین ۰ تا ۹۹ را جمع کنیم تا به مقدار ۴۳ برسیم؟ همانطور که می توانید تصور کنید، هنگام استفاده از یک الگوریتم پیچیده تر و مقادیر بیشتر، احتمال برخورد به شدت کاهش می یابد، اما مفهوم یکسان باقی می ماند.
هر الگوریتم شامل مقداری مبادله بین تلاش محاسباتی، سرعت و خطر برخورد است. الگوریتم CRC-8 سریعتر محاسبه میکند و انرژی کمتری مصرف میکند، اما خطر برخورد دادهها برای دو بلوک منحصربهفرد بسیار بیشتر از خطر برخورد هنگام استفاده از الگوریتم CRC-32 است. پیچیدگی الگوریتم CRC-32 منجر به محاسبات کندتر با استفاده از منابع بیشتر می شود.
نحوه استفاده از CRC در ارتباطات شبکه
چکهای افزونگی چرخهای برای چیزی بیش از یکپارچگی فایل استفاده میشوند. همچنین برای تشخیص خطاهای ترافیک شبکه استفاده می شود. چکهای افزونگی چرخهای یک checksum به بلوکهای داده در حالت استراحت و در حال انتقال اضافه میکنند، که امکان نظارت بر شبکه را در زمان واقعی فراهم میکند. این قابلیتهای نظارتی امکان تشخیص سریعتر خطا و زمان پاسخ را در میان تحلیلگران و مهندسان شبکه فراهم میکند که تاثیر منفی کلی بر شبکه را کاهش میدهد.
با شناسایی خطاها، بهویژه اختلاف بین checksum بلوکهای داده ارسالی و دریافتی، تحلیلگران شبکه و امنیت به طور یکسان میتوانند هم مشکلات واقعی شبکه و هم فعالیتهای بالقوه مخرب را شناسایی کنند. از منظر شبکه، اختلاف checksum می تواند به این معنی باشد که یک دستگاه شبکه با یک گلوگاه (bottleneck) مواجه است یا به طور کامل آفلاین است.
از منظر امنیتی، تشخیص checksum های ناهماهنگ میتواند به این معنی باشد که یکپارچگی شبکه یا فایل به خطر افتاده است، به این معنی که یا ترافیک رهگیری و اصلاح شده است یا محتوای فایل اصلاح شده است.
برای امتحان یک نمونه checksum ، اغلب میتوانید نرمافزاری را از یک سایت معتبر دانلود کنید و مقدار checksum را در یک یادداشت جداگانه کپی کنید. پس از دانلود فایل، می توانید این دستور را در رابط خط فرمان (CLI) یا ترمینال خود وارد کنید:
cksum [file_name]
اگر دستور را در PowerShell اجرا می کنید، این را امتحان کنید:
Get-FileHash [file_name]
الگوریتم دقیق مورد استفاده برای محاسبه مقدار هش ممکن است با یکی از الگوریتمهای CRC که در مورد آن صحبت کردیم متفاوت باشد، اما مفهوم بررسی یکپارچگی یکسان است. وب سایتی که نرم افزار را دانلود کرده اید باید به شما بگوید که از کدام الگوریتم برای محاسبه مقدار هش ارائه شده استفاده شده است.
Interface Statistics و خطاهای CRC چیست؟
چکهای افزونگی چرخهای از checksum برای تشخیص تغییرات در دادههای ارسال و دریافت شده استفاده میکنند، بنابراین منطقی است که CRCها بیشتر برای شناسایی و تعمیر مشکلات شبکه استفاده میشوند. برخی از دلایل رایج خطاهای CRC عبارتند از تداخل الکتریکی، تجهیزات معیوب مانند کابل ها و کانکتورها و مشکلات سخت افزاری.
تداخل الکتریکی میتواند ناشی از سایر دستگاههای الکترونیکی با قدرت سیگنال بالقوه بیشتر باشد که در فرکانس مشابه دستگاهی که مشکلات یکپارچگی دادهها را پخش میکنند، و در برخی موارد حتی میتواند توسط دستگاههای سیمی با مجرای نامناسب و فاصله از سیمهای دیگر ایجاد شود.
کابل ها و کانکتورهای معیوب یکی دیگر از دلایل رایج خطاهای CRC هستند. هنگامی که تجهیزات آسیب می بینند، چه پین های رابط خم شده باشند یا کابل ها فرسوده شده باشند، می تواند منجر به از دست رفتن داده ها شود که ممکن است منجر به اختلاف جمع کنترل و خطاهای CRC شود. خرابیهای سختافزاری، مانند داغ شدن بیش از حد دستگاهها یا اتصالات نامناسب، مانند قرار نگرفتن کامل کارت شبکه در دستگاه، ممکن است باعث ایجاد خطاهای CRC شوند.
صرف نظر از علت مشکل، خطاهای CRC منجر به از دست دادن بسته، کاهش عملکرد و خرابی شبکه می شود. تحلیلگران و مهندسان شبکه باید نرخ خطای CRC (تعداد فریم های خطا در مقایسه با تعداد کلی فریم های دریافتی) را برای تشخیص مشکلات در شبکه های خود نظارت کنند.
علاوه بر این، کشف الگوهایی در میان این خطاها می تواند به محدود کردن دامنه موضوع کمک کند. انجام این کار به تعیین علت اصلی خطاها کمک می کند و به مهندسان شبکه فرصتی می دهد تا قبل از اینکه تأثیر آن بیشتر شود، مشکل را حل کنند.
خرید سرور مجازی در پنج موقعیت جغرافیایی ایران، ترکیه، هلند، آلمان و آمریکا با قابلیت تحویل آنی در پارسدو فراهم است.
بهترین روش ها برای مدیریت خطاهای CRC
بهترین راه برای مدیریت خطاهای افزونگی چرخهای از طریق مانیتور و تجزیه و تحلیل منظم است که شامل نظارت بر بسته های شبکه و آمار و تجهیزات فیزیکی است. مانیتور مداوم احتمال تشخیص زودهنگام را افزایش میدهد، که در نهایت هر گونه خرابی شبکه را کاهش خواهد داد.
استقرار و نگهداری تجهیزات شبکه Failover میتواند به پاسخگویی به خطاهای CRC کمک کند و در عین حال خرابی شبکه و از دست دادن بستههای بیشتر را نیز کاهش دهد. ثبت و ارسال گزارش نیز باید اجرا شود تا اطمینان حاصل کنیم که تحلیلگران شبکه میتوانند علت اصلی مشکلات را در صورت آفلاین شدن یا غیرقابل دسترس بودن دستگاه تعیین کنند.
تعمیر و نگهداری منظم تجهیزات نیز برای مدیریت خطاهای CRC قبل از شروع آنها بسیار مهم است. خطاهای CRC اغلب به مشکلات مربوط به تجهیزات فیزیکی مربوط میشود، خواه دیوایسها به درستی متصل نشده باشند یا تجهیزات آسیب دیده باشند. انجام منظم بازرسیهای فیزیکی راه خوبی برای کاهش خطر خطاهای CRC است.
نتیجه گیری
چکهای افزونگی چرخهای یا CRC، روشی است که برای تایید مطابقت دادههای دریافتی با دادههای ارسال شده توسعه یافته است. CRC ها این اعتبار را از طریق استفاده از الگوریتم های ریاضی به دست می آورند و الگوریتم های مختلفی برای دستیابی به تعادل مناسب سرعت، استفاده از منابع و خطر برخورد وجود دارد. خطاهای Cyclic Redundancy Check گاهی اوقات ممکن است رخ دهد و اغلب نتیجه سخت افزار آسیب دیده یا اتصال نامناسب است.


