


مشاهده پذیری (Observability) به ما اجازه میدهد تا یک سیستم را از بیرون درک کرده و در مورد آن سیستم بدون دانستن عملکرد درونیاش سوال بپرسیم. علاوه بر این، به ما این امکان را میدهد که به راحتی مشکلات جدید را عیب یابی و مدیریت کنیم
مشاهده پذیری چیست؟
معنای لغوی Observability حالت مشاهده پذیر بودن است.
در فناوری اطلاعات، مشاهده پذیری به عنوان توانایی اندازه گیری وضعیت فعلی یک سیستم بر اساس دادههای خروجی (مانند لاگها، متریک و تریس) که تولید میکند، تعریف میشود.
مشاهدهپذیری به ما اجازه میدهد تا یک سیستم را از بیرون درک کرده و در مورد آن سیستم بدون دانستن عملکرد درونیاش سوال بپرسیم. علاوه بر این، به ما این امکان را میدهد که به راحتی مشکلات جدید را عیب یابی و مدیریت کنیم (معلومات ناشناخته – unknown unknowns)، و به ما کمک مینماید به این سوال پاسخ دهیم که «چرا این اتفاق میافتد؟»
سوال پرسیدن در مورد سیستم یعنی توانایی جمع آوری اطلاعات و بینش در مورد نحوه عملکرد و رفتار یک سیستم.
تصور کنید که در حال مدیریت یک وب سایت تجارت الکترونیک با بسیاری از میکروسرویسها مانند خدمات فرانتاند، خدمات محصول، خدمات سبد خرید، خدمات سفارش، خدمات پرداخت و غیره هستید و وبسایت ناگهان کند شده و به آرامی لود میشود.
بدون قابلیت مشاهده، ممکن است مجبور شوید کد، زمان پاسخ پایگاه داده، تاخیر API، تاخیرهای سرویس شخص ثالث و اجزای مختلف را به صورت دستی بررسی کنید تا مشکل شناسایی شود.
ولی با وجود ابزارهای مشاهدهپذیری، میتوانید «سوالاتی بپرسید» مانند:
- میانگین زمان پاسخگویی وب سایت در یک ساعت گذشته چقدر است؟
- آیا جهشی در نرخ خطا وجود دارد؟
- کدام سرویس یا مولفه خاص بیشترین زمان پاسخگویی را دارد؟
- زمان پاسخ کوئری دیتابیس چگونه است؟
- آیا نوع خاصی از درخواست یا تراکنش وجود دارد که با تاخیر مواجه شود؟
- آیا کاهش سرعت در همه کاربران سازگار است یا مختص یک منطقه است؟
این سوالات را میتوان از طریق دادههای ارائه شده توسط لاگهای اپلیکیشنها، متریکها و تریسها پاسخ داد.
- گزارشها رویدادهایی را که در برنامه اتفاق میافتند از طریق لاگ کتابخانهها ثبت میکنند.
- متریکها دادههای عددی در مورد عملکرد سیستم (مانند زمان پاسخ، تعداد درخواستها و غیره) را ارائه میدهند. برنامهها با استفاده از کتابخانهها برای انتشار معیارها ابزارسازی میشوند
- ردیابیها سفر درخواست را از طریق خدمات مختلف در یک سیستم توزیع شده با استفاده از کتابخانههایی مانند OpenTelemetry یا APM (Application Performance Monitoring) ردیابی میکنند.
با تجزیه و تحلیل این دادهها، می توانید مشخص کنید که، برای مثال، کندی سرعت به دلیل یک سرویس خاص است که پاسخ دادن به آن خیلی طول میکشد، شاید به دلیل تغییر اخیر کد یا افزایش لود باشد که امکان حل سریعتر و کارآمدتر مشکل را فراهم میکند.
ممکن است فکر کنید، همه اینها مانند مانیتور معمولی به نظر میرسد. اما این طور نیست. اجازه دهید تفاوت بین مانیتور و مشاهده پذیری را درک کنیم.
تفاوت بین قابلیت مشاهده و مانیتورینگ
برای مهندسان DevOps یا افرادی که به تازگی راه خود را در SRE آغاز کردهاند، واقعا مهم است که تفاوت بین مانیتورینگ و مشاهده پذیری را درک کنند.
این چیزی است که تحقیقات DORA در مورد قابلیت مشاهده و نظارت می گوید.
مانیتورینگ ابزار یا یک راه حل فنی است که به تیمها اجازه میدهد وضعیت سیستمهای خود را مشاهده و درک کنند. مانیتور بر جمع آوری مجموعههای از پیش تعریف شده متریک یا لاگها استوار است.
مشاهده پذیری ابزار یا یک راه حل فنی است که به تیمها اجازه میدهد تا به طور فعال سیستم خود را عیبیابی (دیباگ) کنند. مشاهده پذیری مبتنی بر کاوش ویژگیها و الگوهایی است که از قبل تعریف نشدهاند.
مانیتورینگ در مورد توجه به مسائل شناخته شده و معیارهای اپلیکیشن یا سیستم است که شامل تنظیم هشدارها و آستانههایی برای معیارهای خاص (مانند استفاده از CPU، استفاده از رم، زمانهای پاسخ، زمان اجرای کوئری در دیتابیس، نرخ خطای 4xx، 5xx، و غیره) و سایر KPIهای نظارتی مستند برای اطلاع تیمها در صورت بروز مشکل است.
بنابراین تمرکز اصلی مانیتورینگ، ردیابی وضعیت و سلامت سیستمها بر اساس متریک و لاگهای از پیش تعریف شده است.
به عنوان مثال، یک ابزار مانیتورینگ زمانی که میزان استفاده از CPU سرور از ۸۰% بالاتر میرود یا زمانی که زمان پاسخگویی یک API از ۲ ثانیه بیشتر میشود، هشدار ارسال میکند.
در سوی دیگر، مشاهده پذیری یک گام فراتر میرود و در مورد درک وضعیت داخلی برنامهها و سیستمها با نگاه کردن به خروجیهای آن (مانند لاگها، متریکها و تریسها) است و البته فقط برای دانستن اینکه چه زمانی مشکلی پیش میآید نیست، بلکه درک اینکه چرا اشتباه شده است.
تمرکز کلیدی مشاهده پذیری بیشتر اکتشافی و تحقیقی است و به شما امکان میدهد سوالات دلخواه در مورد رفتار برنامهها بپرسید و مسائلی را که پیش بینی نکردهاید را تشخیص دهید.
به عنوان مثال، هنگامی که یک وب سایت به طور غیرمنتظره شروع به کند شدن میکند، از ابزارهای مشاهده پذیری برای تجزیه و تحلیل الگوهای دادهها، ردیابی درخواستها و بررسی لاگها استفاده میکنید تا تشخیص دهید که استقرار کد اخیر باعث کمبود حافظه و منجر به کاهش زمان پاسخ میشود.
به زبان ساده، مانیتورینگ به شما میگوید که یک سیستم شکست خورده و Observability به شما کمک میکند تا متوجه شوید که چرا آن سیستم شکست خورده است.
اکنون که درک کلی از مشاهده پذیری داریم، اجازه دهید به مفاهیم کلیدی مشاهده پذیری نگاه کنیم.
مفاهیم مشاهده پذیری
سه اصل کلیدی مشاهده پذیری عبارتند از:
- متریک (Metrics)
- لاگ (Logs)
- تریس (Traces)
لاگها (Logs)
لاگ، ثبت یک رویداد در برنامه شما است. یک ورودی لاگ معمولا حاوی اطلاعاتی درباره رویدادی است که رخ داده است، از جمله تایم استمپ، شرح رویداد، سطح شدت و گاهی اوقات کانتکس اضافی مانند ID کاربر یا ID جلسات.
توسعه دهندگان مسئول loggingدر کد هستند. از آنجایی که اکثر کتابخانهها و زبانهای نرمافزار دارای عملکرد داخلی هستند، پیادهسازی لاگها ساده است. در زیر چند نمونه از انواع مختلف فرمتهای لاگ آورده شده است.
- متن ساده (Plain Text): ساده ترین شکل logging به متن قابل خواندن توسط انسان.
- ساختاریافته (Structured): ورودیهای گزارش ساختار یافته در قالب قابل خواندن ماشین (JSON، XML و غیره)
- فرمت باینری (Binary Format): گزارشهای ذخیره شده در فرمت باینری (گزارشهای Protobuf، گزارشهای باینری MySQL، گزارشهای مجله Systemd و غیره)
- فرمت سفارشی (Custom format): برای تامین نیازهای پروژه خاص.
متریک (Metrics)
متریکها، دادههایی هستند که در اعداد اندازه گیری شده در بازههای زمانی نمایش داده میشوند.
به عنوان مثال، متریک node_memory_MemAvailable_bytes در پرومتئوس میزان حافظه موجود را بر حسب بایت نشان میدهد. متریک http_request_duration_seconds مدت زمان درخواستهای HTTP را دنبال میکند.
در اینجا نمونه ای از متریکهای تولید شده توسط Prometheus exporters آورده شده است.
متریکها نقش کلیدی در مشاهده پذیری دارند. با آنها میتوانید وضعیت سیستم خود را در یک نگاه و در طول زمان درک کنید و به شما کمک کند روندها و الگوهای رفتار سیستم را در زمانهای مختلف پیدا کنید.
تریس و اسپن (Traces & Spans)
تریس و اسپن اصطلاحاتی هستند که عمدتا در ردیابی توزیع شده استفاده میشوند.
ردیابی توزیع شده روشی است که برای ردیابی و مانیتور بر جریان درخواستها از طریق سیستمهای توزیع شده، به ویژه در معماری های میکروسرویس استفاده میشود.
بیایید به مثالی از اپلیکیشن تجارت الکترونیکی که با میکروسرویسها ساخته شده است نگاه کنیم.
هنگامی که یک کاربر سفارشی را ارسال میکند، درخواست از طریق چندین سرویس حرکت میکند: ابتدا به سرویس پردازش سفارش برخورد میکند که سپس با موجودی، پرداخت و خدمات حساب کاربری ارتباط برقرار می کند.
ردیابی توزیع شده این درخواست را در همه این سرویسها ردیابی میکند.
trace کل سفر یک درخواست سفارش را از طریق سیستم نشان میدهد. هر ردیابی از چندین Span تشکیل شده است که هر اسپن نشان دهنده یک عملیات یا فرآیند خاص در ردیابی است.
یک span می تواند فراخوانی به یک میکروسرویس، یک جستجوی پایگاه داده یا هر واحد گسسته دیگری از کار باشد.
با تجزیه و تحلیل ردیابیها، توسعه دهندگان می توانند گلوگاهها (bottleneck) را شناسایی کنند، تاثیر اجزای مختلف را بر عملکرد سیستم درک و مشکلات را عیب یابی کنند.
ابزارهای ردیابی متنباز توزیع شده مانند Jaeger یا Zipkin میتوانند توالی فاصلهها را به عنوان یک جدول زمانی نشان دهند و درک جریان و تاخیر درخواستها را آسانتر میکنند.
vps یک ماشین مجازی کامل است که امکان دسترسی SSH طبق آموزش را به آن خواهید داشت.
خرید vps در پنج موقعیت جغرافیایی ایران، ترکیه، هلند، آلمان و آمریکا با قابلیت تحویل آنی در پارسدو فراهم است.
قابلیت مشاهده چگونه کار میکند؟
پلتفرمهای مشاهدهپذیری به طور مداوم تلهمتری عملکرد را با ادغام ابزار دقیق موجود در اجزای کاربردی و زیرساختی و ارائه ابزارهایی برای افزودن ابزار دقیق به این اجزا، شناسایی و جمعآوری میکنند.
بیشتر پلتفرم متریکها، تریسها و لاگها را جمعآوری و آنها را در زمان واقعی وصل کنید تا به تیمهای DevOps، تیمهای مهندسی قابلیت اطمینان سایت (SRE) و پرسنل فناوری اطلاعات اطلاعات متنی کاملی ارائه دهید – چه چیزی، کجا و چرا هر رویدادی که میتواند نشاندهنده، مشارکت یا استفاده باشد. برای رسیدگی به یک مشکل عملکرد برنامه
چرا قابلیت مشاهده مهم است؟
به لطف Observability، تیمهای متقابلی که بر روی سیستمهای بسیار پراکنده کار میکنند، بهویژه در یک محیط سازمانی، میتوانند سریعتر و موثرتر به پرسشهای دقیق واکنش نشان دهند.
میتوان تشخیص داد که چه چیزی باعث کاهش عملکرد برنامه میشود و قبل از اینکه بر عملکرد کلی تاثیر بگذارد یا به مرکز شهر منتهی شود، نسبت به رفع آن اقدام کرد.
مزایای مشاهده پذیری فراتر از موارد استفاده از فناوری اطلاعات است. هنگامی که دادههای مشاهدهپذیری را جمعآوری و بررسی میکنید، پنجرهای به تأثیرات خدمات دیجیتالی شما بر سازمانتان میبینید. این دسترسی به شما امکان می دهد تا نتایج SLO های تجربه کاربری خود را زیر نظر داشته باشید، بررسی کنید که نسخه های نرم افزاری اهداف تجاری را برآورده می کنند، و انتخاب های تجاری را بر اساس آنچه که بیشترین اهمیت را دارد، اولویت بندی کنید.
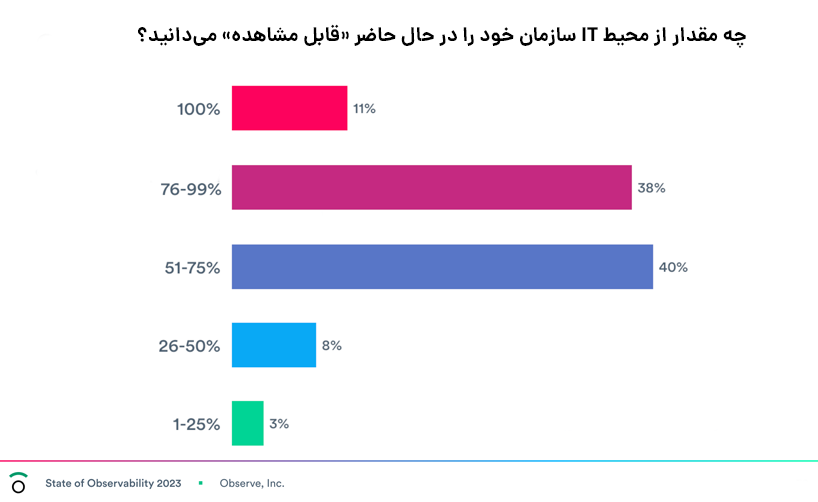
طبق گزارش Observe State of Observability، ۹۱٪ از سازمانها میگویند که در حال حاضر قابلیت مشاهده را تمرین میکنند. با این حال تنها ۱۱ درصد از سازمانها فکر میکنند که کل محیط آنها در حال حاضر قابل مشاهده است.
مزایای مشاهده پذیری چیست؟
مشاهده پذیری مزایای قابل توجهی را برای کاربران نهایی، شرکتها و تیم های فناوری اطلاعات ارائه میدهد. مزایای قابل توجه و چرایی اهمیت مشاهده پذیری به شرح زیر است:
- مانیتور بر عملکرد برنامه: مشاهده کامل end-to-end به کسبوکارها این امکان را میدهد تا مشکلات عملکرد را بهطور قابل توجهی سریعتر شناسایی کنند، حتی آنهایی که توسط معماریهای cloud-native و میکروسرویسها ایجاد میشوند. کارهای بیشتری را میتوان با استفاده از راهحل پیشرفته مشاهده پذیری خودکار کرد که بهره وری و خلاقیت را در میان تیمهای عملیات و برنامهها افزایش میدهد.
- DevSecOps و SRE: مشاهده پذیری یک ویژگی اساسی یک برنامه کاربردی و زیرساختی است که از آن پشتیبانی میکند، نه تنها نتیجه اجرای ابزارهای نوآورانه. طراحان و توسعه دهندگان نرم افزار باید مشاهده آن را آسان کنند. سپس، در طول چرخه حیات تحویل نرمافزار، تیمهای DevSecOps و SRE ممکن است از دادههای قابل مشاهده برای ایجاد برنامههای قویتر، ایمنتر و انعطافپذیرتر استفاده و درک کنند.
- مانیتور زیرساخت، ابر و Kubernetes: یکی از چندین مزیت استفاده از قابلیت مشاهده این است که به مانیتور زیرساخت کمک میکند. این امکان را به تیمهای زیرساخت و عملیات (I&O) میدهد تا بتوانند از زمینه بهبود یافته استفاده کنند که یک راهحل مشاهدهپذیری برای افزایش زمان و عملکرد برنامه، کاهش زمان مورد نیاز برای شناسایی و رفع مشکلات، شناسایی مشکلات تاخیر ابر و بهینهسازی استفاده از منابع برای بهبود مدیریت محیطهای Kubernetes و معماریهای ابری معاصر آنها.
- تجربه کاربر نهایی: یک تجربه کاربری مثبت میتواند شهرت و درآمد کسب و کار را افزایش دهد و به آن مزیت رقابتی بدهد. شرکتها میتوانند با شناسایی و رفع مشکلات قبل از اینکه کاربر نهایی آنها را شناسایی کند و حتی قبل از درخواست آنها، بهبودهایی را اعمال کنند، رضایت و حفظ مشتری را افزایش دهند.
چالشهای مشاهده پذیری چیست؟
اگرچه مشاهده پذیری همیشه دشوار بوده است، پیچیدگی ابرها و تسریع تغییرات، رسیدگی به آن را برای شرکت ها حیاتی کرده است. هنگامی که میکروسرویسها و برنامههای کانتینری درگیر هستند، سیستمهای ابری دادههای تله متری بسیار بالاتری تولید میکنند. علاوه بر این، آنها طیف بسیار گستردهتری از دادههای تلهمتری را نسبت به آنچه که تیمها در گذشته مجبور به رمزگشایی میکردند، تولید میکنند.
در مورد مشاهده پذیری، سازمانها اغلب با مشکلات زیر مواجه می شوند:
- سیلوهای داده: درک وابستگیهای متقابل بین برنامهها، ابرهای مختلف و کانالهای دیجیتال، از جمله وب، موبایل و اینترنت اشیا، به دلیل وجود چندین عامل، منابع دادههای متفاوت و ابزارهای مانیتورینگ سیلو، چالش برانگیز است.
- حجم، سرعت، تنوع و پیچیدگی: در زیرساختهای ابری مدرن که دائم در حال تکامل هستند مانند AWS، Azure و Google Cloud Platform، حجم عظیم دادههای خام تولید شده از هر مولفه یافتن پاسخ (GCP) را تقریبا غیرممکن میکند. توانایی Kubernetes و کانتینرها برای چرخش سریع به بالا و پایین نیز این را نشان میدهد.
- عدم وجود پیش تولید: علیرغم آزمایش بار در پیش تولید، توسعه دهندگان هنوز ابزاری برای مشاهده یا درک اینکه چگونه کاربران واقعی بر برنامهها و زیرساختها قبل از پوش کردن کد به پروداکشن تاثیر میگذارند، ندارند.
- اتلاف وقت در عیب یابی: تیمهایی از برنامه، عملیات، زیرساخت، توسعه و تجربه دیجیتال برای عیب یابی و تلاش برای مشخص کردن منبع مشکلات وارد میشوند. در نتیجه، زمان ارزشمندی برای حدسهای علمی و تلاش برای درک دورسنجی از دست میرود.
چگونه قابلیت مشاهده با DevOps ارتباط دارد؟
در DevOps، مشاهده پذیری ضروری است. نقش مهمی در فرآیند DevOps ایفا میکند زیرا به تیمها اجازه میدهد
- شناسایی مشکلات به صورت real-time
- دیباگ با استفاده از ابزارهای مشاهده پذیری برای ردیابی علت اصلی
- بهینه سازی عملکرد
- بهبود مستمر نرم افزار و زیرساخت
جمعبندی
یک سیستم مشاهده پذیری باید برای پلتفرم مورد نظر خود مناسب باشد. در فقدان آن، ممکن است یا به یک سیستم دست و پا گیر تبدیل شود که هزینه های عملیاتی را بالا میبرد یا غیر قابل توجه باشد و دید کمی ارائه دهد. بنابراین، طرح باید موارد اصلی را که طراحی سازمانی باید امکانپذیر کند، مشخص و نامگذاری کند.
بدون این سوگیری، مشاهده پذیری خطر تبدیل شدن به شبکهای گیج کننده از مسائل متضاد را دارد که ممکن است تجربه و پشتیبانی منسجم و سازگار پیش بینی شده کاربر را ارائه نکند.


