


اگر میخواهید درک کنید کدامیک از آپتایم یا دسترسیپذیری را برای بهبود قابلیت اطمینان برنامه خود استفاده کنید؟ در ادامه مطلب، تفاوت بین این دو، استفاده از آنها و نحوه اندازه گیری آنها را بیان نموده و به روشهای صحیح اندازه گیری قابلیت اطمینان اشاره میکنیم.
وقتی نوبت به اندازه گیری قابلیت اطمینان برنامه میرسد، ما معمولا از آپ تایم استفاده می کنیم. Uptime به مدت زمانی که یک سرویس راه اندازی و در حال اجرا است اشاره دارد و به طور کلی به صورت درصد نشان داده میشود. با این حال، برای بهبود تجربه کاربر، باید روی در دسترس بودن، از جمله مولفه تجربه کاربر تمرکز کرد.
آپتایم (Uptime) چیست؟
Uptime به زمانی اشاره دارد که یک برنامه در طول یک دوره راه اندازی و اجرا میشود. به عنوان مثال، اگر برنامه شما در ۳۰ روز گذشته هیچ قطعی نداشته است، شما ۱۰۰٪ آپتایم داشتهاید. اگر قطعی یک روزه داشت، زمان آپتایم ۹۶.۶۷ درصد است. Uptime معمولا به عنوان درصدی از زمان راه اندازی و اجرا شدن یک برنامه نمایش داده میشود.
در دسترس بودن (availability) چیست؟
در دسترس بودن به درصد زمانی اشاره دارد که برنامه شما به درستی به کاربران خود خدمات ارائه میدهد. توجه داشته باشید که برای اندازهگیری دقیق در دسترس بودن، باید جزء تجربه کاربر را نیز لحاظ کنیم.
بسیاری از سازمانها فقط از زمان استفاده میکنند تا به در دسترس بودن اشاره کنند. فرمول محاسبه در دسترس بودن در این مورد به شرح زیر است:

همچنین میتوانید با استفاده از فرمولی که میانگین زمان شکست (MTTF) و میانگین زمان تعمیر (MTTR) را در نظر می گیرد، در دسترس بودن را اندازه گیری کنید. آن فرمول به شرح زیر است.
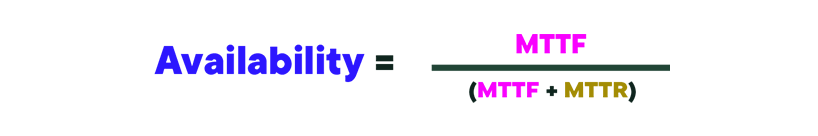
MTTF به میانگین زمان سپری شده قبل از وقوع خرابی اشاره دارد. MTTR به میانگین زمان بازیابی سیستم برای عملیاتی شدن کامل پس از قطعی اشاره دارد.
از این فرمول، به راحتی می توانید چند مشاهدات را استخراج کنید:
الف) هرچه MTTR کوتاهتر باشد، در دسترس بودن بهتر است زیرا MTTR در مخرج است. به همین دلیل است که داشتن ابزارهای لازم برای عیبیابی، از جمله یک سیستم مشاهدهپذیری سرتاسر قابل اعتماد، برای دسترسی بیشتر ضروری است.
ب) زمانی که قطعی کمتری داشته باشیم (خرابی کمتر) در دسترس بودن بیشتر خواهد بود. به عنوان مثال، اگر سرویس شما هر روز به مدت ۵ دقیقه از کار بیفتد، در دسترس بودن شما را میتوان به صورت زیر محاسبه کرد:
MTTF = 24 hours
MTTR = 5 minutes
Availability = 24 / ( 24 + 5/60) = 99.65%
با این حال، اگر درخواست شما یک بار در ماه به مدت ۵ دقیقه با شکست مواجه شد:
MTTF = 30 days = 30 X 24 = 720 hours
MTTR = 5 minutes
Availability = 720 / ( ۷۲۰ + ۵/۶۰ ) = 99.۹۹%
اکنون میتوانید اهمیت خاموشیهای کمتر و زمان تعمیر کوتاهتر را ببینید.
جدول در دسترس بودن
جدول زیر مدت زمانی را نشان می دهد که برنامه شما میتواند برای یک دوره زمانی برای یک هدف در دسترس بودن معین در دسترس نباشد.
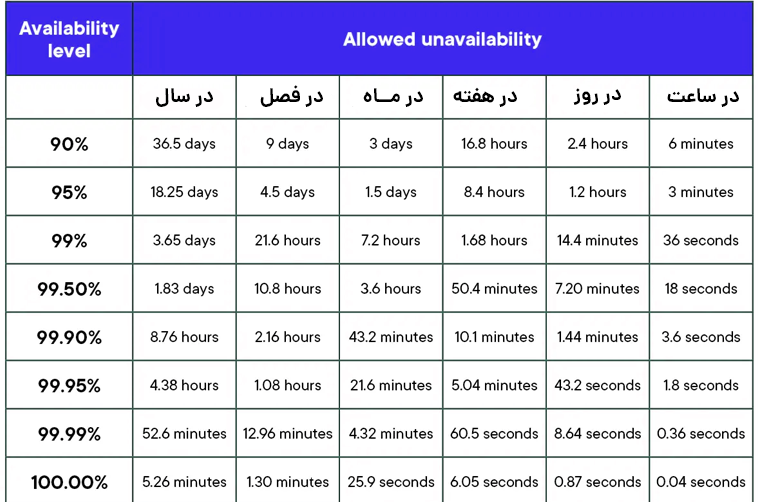
به عنوان مثال، برای ۹۹.۹۹٪ در دسترس بودن، یک برنامه میتواند حداکثر ۵۲.۶ دقیقه در سال خرابی داشته باشد.
اندازه گیری دقیق MTTF و MTTR میتواند چالش برانگیز باشد. در عمل، مجموعهای از SLO به خوبی تعریف شده (Service Level Objectives) که تجربه کاربر را در بر میگیرد، میتواند برای اندازه گیری قابلیت اطمینان استفاده شود. اکنون، بیایید ببینیم که برای بالا بردن قابلیت اطمینان برنامه خود چه چیزی را باید اندازه گیری کنید.
خرید سرور مجازی در پنج موقعیت جغرافیایی ایران، ترکیه، هلند، آلمان و آمریکا با قابلیت تحویل آنی در پارسدو فراهم است.
چه معیارهایی را باید اندازه گیری کنم؟
از میان بسیاری از معیارهایی که میتوان با استفاده از ابزارهای نظارتی اندازهگیری کرد، باید آنهایی را که مستقیم بر تجربه کاربر تاثیر میگذارند، با دقت انتخاب کنیم. به عنوان مثال، در حالی که اندازهگیری میزان استفاده از CPU سرورهای شما میتواند اطلاعات ارزشمندی برای عیبیابی ارائه دهد، اما آنچه را که کاربران تجربه میکنند آشکار نخواهد کرد. معیار بهتری برای اندازه گیری تاخیر (response time) است که کاربر تجربه میکند.
در مهندسی قابلیت اطمینان سایت، معیارهایی که برای استخراج هدف سطح خدمات (SLO) اندازه گیری میکنیم، شاخصهای سطح خدمات (SLI) نامیده می شوند. من توصیه های خود را برای SLI های خوب در هر نوع برنامه در زیر ارائه خواهم کرد:
توصیه های SLI (شاخص های سطح خدمات)
- اپلیکیشنهای وب
اینها برنامههایی با رابط مرورگر وب هستند که کاربران میتوانند با آنها تعامل داشته باشند. ممکن است یک یا چند سرویس بکاند وجود داشته باشد که برنامه وب ممکن است به آنها وابسته باشد. نمونهای از یک برنامه وب میتواند یک وب سایت تجارت الکترونیک آنلاین باشد که در آن افراد میتوانند کالاها را خریداری کنند. SLI ها برای این نوع برنامه عبارتند از:
- تعداد درخواستهای HTTP که با موفقیت تکمیل شدند (خانواده کد وضعیت HTTP 200)، در وب سرور یا لود بالانسر اندازهگیری شد.
- زمان تاخیر (پاسخ) درخواستهای وب بر حسب میلیثانیه، اندازهگیری شده در وب سرور یا لود بالانسر
- زمان پاسخگویی توابع خاص بر حسب میلی ثانیه به عنوان مثال، افزودن یک کالا به سبد خرید، تکمیل خرید، ورود به برنامه و غیره.
- API ها
معمولا خدمات خرد هستند که عملکردهای خاصی را از طریق APIها ارائه میدهند. به عنوان مثال، یک سرویس احراز هویت میتواند کاربری را که از طریق مرورگر وب وارد میشود، احراز هویت کند. SLI ها برای این نوع حجم کاری مشابه موارد مربوط به برنامه های کاربردی وب هستند.
- تعداد خطاهای HTTP 500 (خطاهای سرور داخلی) اندازه گیری شده در API Gateway یا لود بالانسر
- تعداد درخواستهای HTTP که با موفقیت تکمیل میشوند (خانواده کد وضعیت HTTP 200)، اندازهگیری شده در API Gateway یا لود بالانسر
- زمان تاخیر (پاسخ) درخواستهای API بر حسب میلیثانیه، اندازهگیری شده در API Gateway یا لود بالانسر
- اپلیکیشنهای بکاند
برنامههای کاربردی بکاند هستند که دادهها را پردازش میکنند. یک مثال کلاسیک از این میتواند یک برنامه انتقال فایل باشد که فایلها را بین سیستمها، اغلب بین دو شرکت، جابه جا میکند. SLI های پیشنهادی در اینجا عبارتند از:
- تعداد دفعات ناموفق فایل در روز
- درصد رکوردهای ناموفق در هر فایل. در صورت وجود، نوع خرابی را دسته بندی کنید. به عنوان مثال، خرابی ممکن است به دلیل دادههای نادرست، مقصد نادرست، بررسی اعتبار داده ها و غیره باشد.
- میانگین زمان پردازش و زمان پردازش P95 دادهها
- اپلیکیشنهای دسکتاپ
برنامههای کلاینت ضخیم هستند که روی دسکتاپ کاربران اجرا میشوند. آنها معمولا برای دسترسی به داده ها به یک سیستم Backend متصل می شوند. SLI های توصیه شده در اینجا عبارتند از:
- زمان راه اندازی برنامه: بر حسب میلی ثانیه اندازه گیری میشود
- تاخیر برای توابع خاص: به عنوان مثال، یک تابع آپلود فایل.
- تعداد خطاهای سمت کلاینت
- نسبت ضربه به کش (Cache-hit ratio): به صورت درصد اندازه گیری میشود
- پردازش کلان دادهها
این اپلیکیشنهای بکاند، مقادیر زیادی داده (چند ترابایت در روز) را پردازش میکنند، شاید برای موارد استفاده از یادگیری ماشین. آنها همچنین میتوانند خطوط لوله دادهای باشند که دادهها را تجزیه، فیلتر و انتقال میدهند. در اینجا SLI ها برای این نوع برنامهها آمده است:
- از دست دادن دادهها (Data loss)، به عنوان درصد سوابق اندازه گیری میشود
- تعداد تلاشهای مجدد ناموفق
- شکست در تجزیه دادهها
- Queue fill ratio (که نشان می دهد پیام ها یا رکوردها شروع به صف میکنند)
- پلتفرمهای مانیتورینگ
پلتفرمهای قابل مشاهده هستند که برنامههای شما را مانیتور میکنند. ما باید قابلیت اطمینان این سیستمها را اندازه گیری کنیم تا مطمئن شویم در صورت نیاز در دسترس هستند. در اینجا SLI های توصیه شده وجود دارد:
- در دسترس بودن: به عنوان درصد زمانی که کاربر میتواند metrics را مشاهده کند و پرس و جوها را با موفقیت انجام دهد اندازه گیری میشود.
- زمان پاسخ برای جستجوها و بارگذاری داشبورد: باید از یک پروب مصنوعی (synthetic probe) برای اندازهگیری آن استفاده کنید تا بتوانید آن را با زمان پاسخدهی شناخته شده مقایسه کنید.
- تازگی دادهها (Data freshness): متریکها با چه سرعتی وارد پلتفرم میشوند
- دقت دادهها: باز هم، یک synthetic probe میتواند به اندازه گیری دقت دریافت و بازیابی دادهها کمک کند.
نتیجه
قابلیت اطمینان یک ویژگی حیاتی برای هر برنامه موفق است. برای حفظ سطوح بالایی از قابلیت اطمینان، باید به طور مداوم معیارهای صحیح را اندازه گیری کرد. در حالی که یک متریک زمان کار ساده میتواند حس اطمینان را ایجاد کند، برای اندازهگیری دقیق قابلیت اطمینان، باید معیارهایی را اندازهگیری کرد که مستقیم بر تجربه کاربر تاثیر میگذارند. برای این منظور، باید اهداف سطح سرویس (SLO) و شاخصهای سطح سرویس (SLI) را تعریف کنید که با نوع برنامه شما و عملکردهای خاصی که ارائه میکند مطابقت داشته باشد.


