


سیستمهای ذخیرهسازی (استوریج) در عصر شکوفایی محاسبات ابری، بستری است که ارزش تامل دارد. با وجود ابزارهای متعددی که یک سیستم وجود دارد، دانستن اینکه چه چیزی را برای چه هدفی انتخاب کنید میتواند دلهره آور باشد. مطالعه این مطلب، یک نمای کلی از رایجترین سیستمهای ذخیره سازی موجود ارائه میدهد و به طور عمیق به مقایسه مقایسه Ceph ، GlusterFS، MooseFS ، HDFS و DRBD میپردازد.
در مقایسه Ceph ، GlusterFS، MooseFS ، HDFS و DRBD که همگی سیستمهای فایل توزیعشده هستند که برای ذخیرهسازی دادهها در مقیاس بزرگ استفاده میشوند.
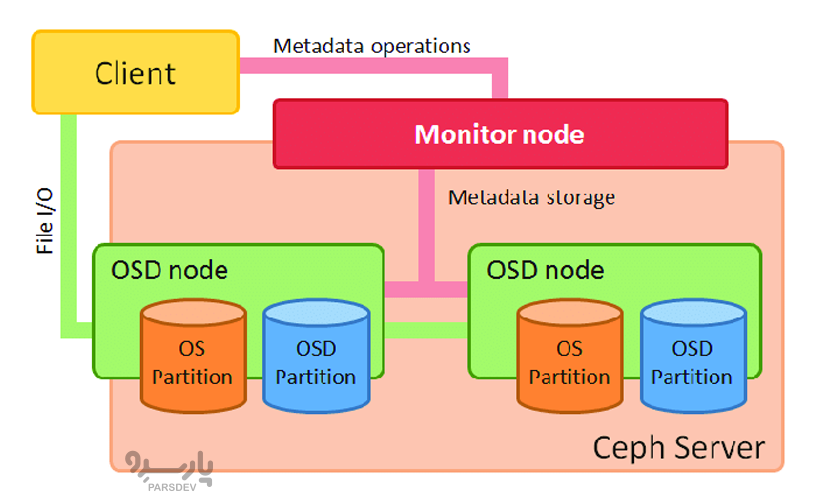
سف (Ceph) چیست؟
Ceph یک سیستم ذخیره سازی قوی است که به طور منحصر به فرد آبجکت، بلوک (با RBD) و ذخیره سازی فایل را در یک سیستم یکپارچه ارائه میدهد. چه بخواهید دستگاههای بلوک (block devices) را به ماشینهای مجازی خود وصل کنید یا دادههای بدون ساختار را در یک آبجکت استور (object store) ذخیره کنید، Ceph همه آنها را در یک پلتفرم ارائه میکند و چنین انعطافپذیری زیبایی را به دست میآورد. همه چیز در Ceph به شکل اشیاء ذخیره میشود و RADOS object store بدون توجه به نوع داده آنها مسئول ذخیره سازی این اشیا است. لایه RADOS اطمینان حاصل میکند که دادهها همیشه در حالت ثابت (consistent state) باقی میمانند و قابل اعتماد هستند. برای سازگاری دادهها، همانندسازی دادهها، تشخیص شکست و بازیابی و همچنین انتقال دادهها و تعادل مجدد در میان گرههای کلاستر را انجام میدهد.
سف یک POSIX-compliant network file system (CephFS) را ارائه میدهد که هدف آن عملکرد بالا، ذخیره سازی دادههای بزرگ و حداکثر سازگاری با برنامههای قدیمی است. دسترسی یکپارچه به اشیا از پیوندهای زبان مادری(RGW) یا radosgw استفاده میکند، یک اینترفیس REST که با برنامههای نوشته شده برای S3 و Swift سازگار است. از سوی دیگر، دسترسی به ایمیجهای block device که به صورت striped هستند و در کل کلاستر ذخیره سازی تکرار میشوند توسط Ceph’s RADOS Block Device (RBD) ارائه می شود.
Ceph راهکاری نرم افزاری است که با توجه به نیاز روز افزون به رشد و پیشرفت ارائه شده است. اطلاعات بیشتر در مورد Ceph را در این مطلب مطالعه نمائید.
Ceph چیست و چه کاربردی دارد؟
ویژگیهای Ceph
- یک پلتفرم واحد، باز و یکپارچه: ذخیره سازی بلوک، شی و فایل در یک پلتفرم ترکیب شده است، از جمله جدیدترین CephFS
- قابلیت همکاری: میتوانید از Ceph Storage برای ارائه یکی از سازگارترین سرویسهای وب آمازون (AWS) S3 در میان سایر موارد استفاده کنید.
- Thin Provisioning – تخصیص فضا فقط مجازی است و فضای دیسک واقعی در صورت نیاز ارائه می شودکه این انعطاف پذیری و کارایی بسیار بیشتری را فراهم میکند.
- ریپلیکیشن (Replication) – در ceph استوریج تمام دادههای ذخیره شده به طور خودکار از یک گره به چندین گره دیگر تکرار میشوند. سه تکرار از دادههای شما در هر زمان در کلاستر وجود دارد.
- خود درمانی(Self-healing) : مانیتورها به طور مداوم مجموعه دادهها را کنترل میکنند. در صورت گم شدن یکی از سه نسخه، یک کپی به طور خودکار ایجاد میشود تا همیشه سه نسخه در دسترس باشد.
- در دسترس بودن زیاد: در Ceph Storage، تمام دادههایی که ذخیره میشوند به طور خودکار از یک گره به چندین گره دیگر تکرار میشوند. این بدان معنی است که در صورتی که یک مجموعه داده در یک گره معین به هم بخورد یا به طور تصادفی حذف شود، دو نسخه دیگر از همان گره وجود دارد که دادههای شما را بسیار در دسترس قرار میدهد.
- Ceph قدرتمند است – کلاستر شما را میتوان برای هر چیزی استفاده کرد. اگر میخواهید دادههای بدون ساختار را ذخیره کنید یا ذخیرهسازی بلوکی برای دادههای خود فراهم کنید یا یک فایل سیستم ارائه کنید یا میخواهید برنامههای کاربردی شما مستقیم از طریق librados با فضای ذخیرهسازی تماس بگیرند، همه آنها را در یک پلتفرم دارید.
- مقیاس پذیری: Ceph به صورت کلاستری کار میکند که در صورت نیاز میتوان آنها را افزایش داد و از این رو نیازهای مقیاس آینده را تامین میکند.
- Ceph برای ذخیره سازی بلوک، داده های بزرگ یا هر برنامه دیگری که مستقیم با librados ارتباط برقرار میکند مناسب است.
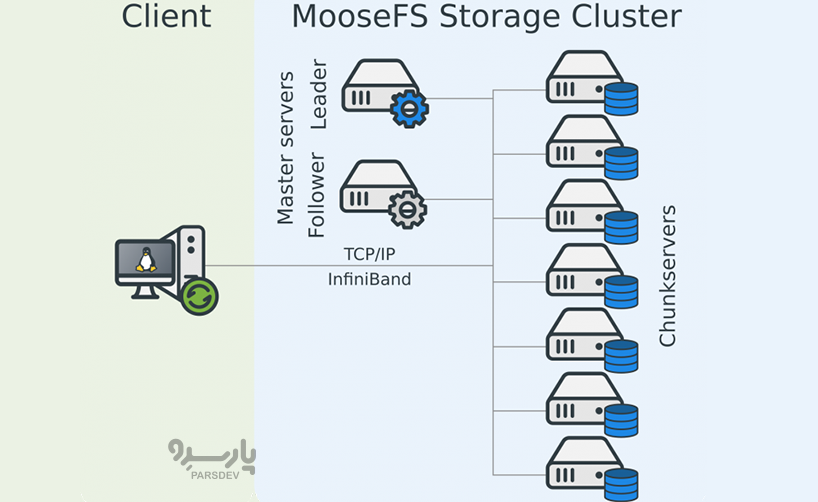
موس اف اس (MooseFS) چیست؟
MooseFS که حدود ۱۲ سال پیش به عنوان اسپین آف Gemius (یک شرکت اروپایی پیشرو که اینترنت را در بیش از ۲۰ کشور اندازه گیری می کند) معرفی شد، یک مفهوم پیشرفت در صنعت ذخیره سازی دادههای بزرگ است که امکان میدهد تا با استفاده از سخت افزار کالای مقرون به صرفه، ذخیره سازی داده و پردازش داده را در یک واحد ترکیب کنید.
ویژگیهای MooseFS
- افزونگی(Redundancy): همه اجزای سیستم ریداندنت (Redundant) هستند و در صورت خرابی، مکانیزم Failover خودکار وجود دارد که برای کاربر شفاف است.
- محاسبات روی گرهها: پشتیبانی از زمان بندی (scheduling) محاسبات بر روی گرههای داده برای TCO کلی سیستم با استفاده از منابع CPU و منابع حافظه.
- اسنپ شات: تهیه آنی و بدون وقفه فایل سیستم در هر مقطع زمانی خاص. این ویژگی برای راهکارهای پشتیبان گیری آنلاین ایده آل است.
- ذخیره سازی لایهای (Tiered Storage): تخصیص دستههای مختلف داده به انواع مختلف رسانههای ذخیره سازی برای کاهش هزینه کل ذخیره سازی. دادههای داغ (Hot Data) را می توان بر روی دیسکهای SSD سریع ذخیره کرد و دادههای کم استفاده را میتوان به هارد دیسکهای مکانیکی ارزانتر و کندتر منتقل کرد.
- نیتیو کلاینت: عملکرد بهبودیافته از طریق مولفه های کلاینت (mount) اختصاصی که مخصوص سیستم های Linux، FreeBSD و MacOS طراحی شده است.
- سطل زباله گلوبال (Global Trash): یک فضای مجازی و گلوبال برای اشیاء حذف شده، قابل تنظیم برای هر فایل و دایرکتوری. با کمک این ویژگی سودمند، دادههای حذف شده تصادفی به راحتی قابل بازیابی هستند.
- محدودیتهای سهمیه(Quota Limits): مدیر سیستم این قابلیت را دارد که محدودیتهایی را برای محدود کردن ظرفیت ذخیرهسازی داده در هر دایرکتوری تعیین کند.
- Rolling Upgrades: امکان ارتقاء یک نود در یک زمان، تعویض سخت افزار و افزودن آن، بدون ایجاد اختلال در سرویس. این ویژگی به شما امکان میدهد تا پلتفرم سخت افزاری را به روز کرده و بدون هیچ خرابی نگهداری کنید.
- بازیابی سریع دیسک: در صورت خرابی هارد دیسک یا سخت افزار، سیستم فورا تکثیر دادههای موازی را از کپیهای اضافی به سایر منابع ذخیره سازی موجود در سیستم آغاز می کند. این فرآیند بسیار سریعتر از روش سنتی بازسازی دیسک است.
- موازی سازی: تمام عملیات I/O را در رشتههای موازی اجرا انجام میدهد تا عملیات خواندن/نوشتن با کارایی بالا را ارائه دهد.
- رابطهای مدیریتی: مجموعهای غنی از ابزارهای مدیریتی مانند رابط های مبتنی بر خط فرمان و رابطهای مبتنی بر وب را ارائه میدهد.
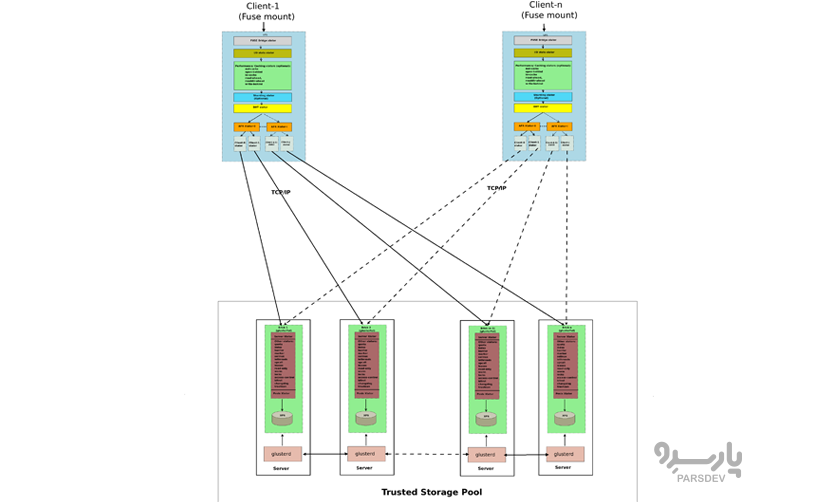
گلاستر اف اس (GlusterFS) چیست؟
گلستر یک فایل سیستم شبکهای مقیاس پذیر رایگان و متنباز است. با استفاده از سختافزار معمولی، میتوانید راهحلهای ذخیرهسازی بزرگ و توزیعشده را برای پخش رسانه، تجزیه و تحلیل دادهها و سایر کارهایی که پهنای باند و داده فشرده دارند ایجاد کنید. سیستمهای ذخیرهسازی Scale-out مبتنی بر GlusterFS برای دادههای بدون ساختار مانند اسناد، تصاویر، فایلهای صوتی و تصویری و فایلهای لاگ مناسب هستند. به طور سنتی، فایل سیستمهای توزیع شده به سرورهای متادیتا متکی هستند، اما گلستر آنها را حذف میکند. سرورهای متدیتا یک نقطه شکست هستند و میتوانند گلوگاهی برای مقیاس بندی باشند. در عوض، گلستر از مکانیسم هش برای یافتن دادهها استفاده میکند.
ویژگیهای گلاستر:
- مقیاس پذیری: سیستم ذخیره سازی مقیاس پذیر که کشش(elasticity) و quotas را فراهم میکند.
- اسنپ شات: حجم و سطح فایل در دسترس است و آن اسنپ شات را میتوان مستقیم توسط کاربران درخواست کرد، به این معنی که کاربران برای ایجاد آنها نیازی به مدیران ندارند.
- بایگانی(Archiving): بایگانی در هر دو صورت read-only و write once read many (WORM) پشتیبانی می شود.
- برای عملکرد بهتر، Gluster دادهها، متادیتا و ورودیهای دایرکتوری را برای readdir() ذخیره میکند.
- ادغام(Integrations): گلستر با مدیر مجازی سازی oVirt و همچنین مانیتور Nagios برای سرورها در میان سایر موارد یکپارچه شده است.
- بیگ دیتا (Big Data): برای کسانی که میخواهند تجزیه و تحلیل دادهها را با استفاده از دادههای یک فایل سیستم گلستر انجام دهند، یک Hadoop Distributed File System (HDFS) پشتیبانی میکند.
- libgfapi: برنامهها میتوانند از libgfapi برای دور زدن سایر روشهای دسترسی و صحبت مستقیم با Gluster استفاده کنند. این برای بارهای کاری که به سوئیچ های context یا کپی از و به فضای کرنل حساس هستند خوب است
مقایسه Ceph ، GlusterFS، MooseFS ، HDFS و DRBD نشان میدهد که هر یک از این فناوریها ویژگیهای منحصربهفردی دارند. بهعنوانمثال، Ceph بهدلیل معماری بدون نقطه شکست و قابلیت مقیاسپذیری بالا محبوب است، درحالیکه GlusterFS برای سادگی و مدیریت آسان شناخته میشود. MooseFS نیز عملکرد بالایی در پردازش فایلهای بزرگ ارائه میدهد. از سوی دیگر، HDFS برای پردازش دادههای کلان بهینه شده و DRBD بیشتر برای تکرار دادهها در سطح بلوک استفاده میشود.
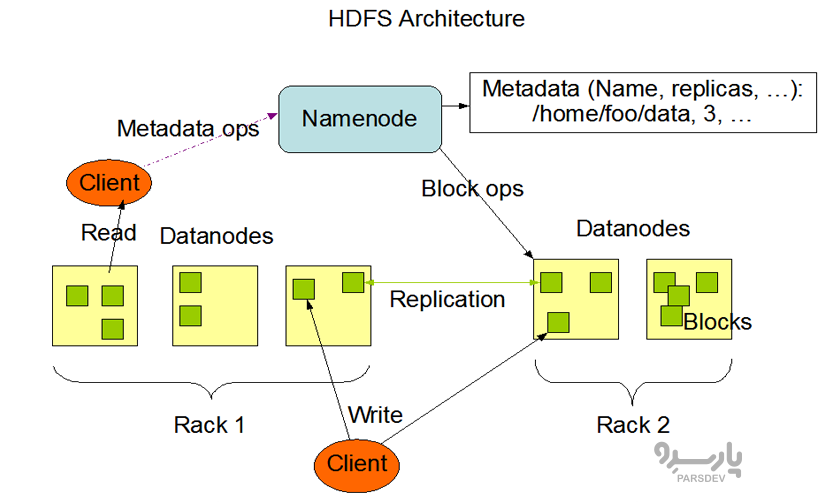
هدوپ (HDFS) چیست؟
Hadoop Distributed File System (HDFS) یک فایل سیستم توزیع شده است که امکان ذخیره و بازیابی چندین فایل را همزمان با سرعت بالا فراهم میکند و به راحتی بر روی سخت افزار کالا (commodity hardware) اجرا میشود و عملکرد پردازش دادههای بدون ساختار را فراهم میکند. این امکان دسترسی با توان بالا به دادههای برنامه را فراهم نموده و برای برنامههایی که مجموعه دادههای بزرگی دارند مناسب است. HDFS به همراه Hadoop YARN، Hadoop MapReduce و Hadoop Common جزء اصلی Hadoop و یکی از اجزای اساسی فریمورک Hadoop است.
ویژگیهای HDFS
- تکرار دادهها (Data Replication)
HDFS به گونهای طراحی شده است که فایلهای بسیار بزرگ را به طور قابل اعتماد در سراسر ماشینها در یک کلاستر بزرگ ذخیره میکند. هر فایل را به صورت دنبالهای از بلوکها ذخیره مینماید. همه بلوکهای یک فایل به جز آخرین بلوک یک اندازه هستند. بلوکهای یک فایل برای تحمل خطا تکرار میشوند.
- فضای نام فایل سیستم (File System Namespace)
HDFS از سازماندهی فایل سلسله مراتبی سنتی پشتیبانی میکند. یک کاربر یا یک برنامه کاربردی می تواند دایرکتوری ایجاد و فایلها را در داخل این دایرکتوریها ذخیره کند. سلسله مراتب فضای نام فایل سیستم مشابه اکثر فایل سیستمهای موجود است. میتوان فایلها را ایجاد و حذف ، یک فایل را از یک دایرکتوری به پوشه دیگر منتقل کرد یا نام یک فایل را تغییر داد. HDFS هنوز سهمیههای کاربر(user quotas) را اجرا نمیکند. HDFS از لینکهای سخت یا لینکهای نرم پشتیبانی نمیکند.
- قدرتمند
هدف اصلی HDFS ذخیره سازی قابل اعتماد دادهها حتی در صورت وجود خرابی است. سه نوع رایج خرابی عبارتند از خرابیهای NameNode، خرابیهای DataNode و پارتیشنهای شبکه.
- دسترسی
HDFS را میتوان از طریق برنامههای کاربردی به روشهای مختلف دسترسی داشت. در اصل، HDFS یک API جاوا را برای استفاده برنامهها فراهم میکند. یک wrapper زبان C برای این API جاوا نیز موجود است. علاوه بر این، یک مرورگر HTTP نیز می تواند برای مرور فایلهای یک نمونه HDFS استفاده شود. کار برای افشای(expose) HDFS از طریق پروتکل WebDAV در حال انجام است.
- مقیاس پذیری
HDFS به گونهای طراحی شده است که فایلهای بسیار بزرگ را به طور قابل اعتماد در سراسر ماشینها در یک کلاستر بزرگ ذخیره میکند. بسته به نیازهای مورد نظر در آن زمان، کلاستر را میتوان افزایش یا کاهش داد.
- در دسترس بودن زیاد
فایل سیستم توزیع شده Hadoop به گونهای طراحی شده است که فایلهای بسیار بزرگ را به طور قابل اعتماد در بین ماشینها در یک کلاستر بزرگ و هر فایل را به صورت دنباله ای از بلوکها ذخیره میکند. همه بلوکهای یک فایل به جز آخرین بلوک یک اندازه هستند. بلوکهای یک فایل برای تحمل خطا تکثیر میشوند و از این رو دادهها در صورت بروز هر گونه خرابی کاملا در دسترس هستند.
سرور مجازی یک ماشین مجازی کامل است که امکان تغییر در سیستم عامل آن برای کاربر فراهم میباشد.
خرید سرور مجازی در پنج موقعیت جغرافیایی ایران، ترکیه، هلند، آلمان و آمریکا با قابلیت تحویل آنی در پارسدو فراهم است.
دی آر دی بی (DRDB) چیست؟
DRBD یک سیستم ذخیره سازی تکراری توزیع شده است که به عنوان یک درایور کرنل، چندین برنامه مدیریت فضای کاربر و برخی از اسکریپتهای پوسته پیاده سازی شده است. دستگاه بلوک تکراری توزیع شده (Distributed Replicated Block Device) دستگاههای بلوک را در بین میزبانهای متعدد برای دستیابی به کلاسترهای بسیار در دسترس منعکس میکند. کلاسترهای مبتنی بر DRBD اغلب برای افزودن تکرار همزمان و در دسترس بودن بالا به سرورهای فایل، پایگاه دادههای رابطهای (مانند MySQL) و بسیاری از بارهای کاری دیگر استفاده میشوند. یک پیاده سازی DRBD میتواند به عنوان پایه یک فایل سیستم دیسک مشترک، یک دستگاه بلوک منطقی دیگر (مانند LVM)، یک فایل سیستم معمولی یا هر برنامه کاربردی که نیاز به دسترسی مستقیم به یک دستگاه بلوک دارد، استفاده شود.
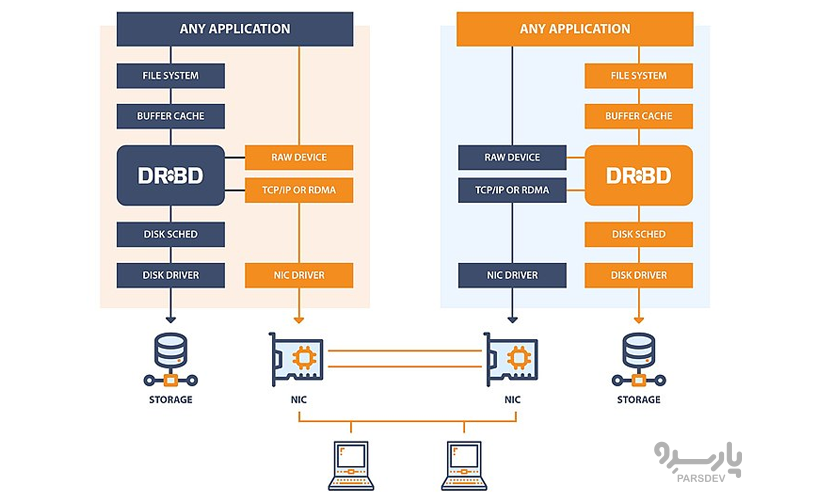
ویژگیهای DRDB
- DRDB دارای احراز هویت shared-secret است
- با LVM سازگار است.
- پشتیبانی برای ادغام عامل منبع heartbeat/pacemaker وجود دارد
- پشتیبانی برای لودبالانسینگ درخواستهای خوانده شده وجود دارد</li><li>تشخیص خودکار به روزترین دادهها پس از شکست کامل
- همگام سازی مجدد دلتا (Delta resynchronisation)
- استقرار موجود را می توان با DRBD بدون از دست دادن داده پیکربندی کرد
- مدیریت خودکار پهنای باند
- پارامترهای تنظیم قابل تنظیم
- تایید آنلاین دادهها با peer
- در دسترس بودن: Block Device میرورها موجب میشوند تا به کلاسترهای بسیار در دسترس دست یابد.
- با راه حل های مجازی سازی مانند Xen ادغام میشود و ممکن است هم در زیر و هم در بالای پشته LVM لینوکس استفاده شود.
در این مطلب به مقایسه Ceph ، GlusterFS، MooseFS ، HDFS و DRBD پرداختیم، سیستمهای فوق و ویژگیهای آنها نمای کلی از درون آنها و آنچه در یک نگاه هستند ارائه میدهند. این بسته به نوع پروژه و اهداف شما دارد که کدام یک از این سیستمهای ذخیرهسازی (استوریج) را برگزیده و پیاده سازی نمائید.


