


در دنیای امروز، با رشد دادهها و نیاز به پردازش سریع آنها، پایگاههای داده NoSQL بیش از گذشته مورد توجه قرار گرفتهاند. یکی از گزینههای پیشرو در این حوزه ScyllaDB است که به دلیل عملکرد بالا، تاخیر کم و مقیاسپذیری عالی، به یکی از محبوبترین پایگاههای داده توزیعشده تبدیل شده است. در این مطلب به بررسی ScyllaDB، نحوه عملکرد، معماری، مقایسه آن با رقبا و بهترین کاربردهای آن خواهیم پرداخت.
پایگاه داده NoSQL چیست؟
یک پایگاه داده NoSQL (NoSQL DB) برای مدیریت حجم عظیمی از داده های توزیع شده طراحی شده است. سیستم های مدیریت پایگاه داده NoSQL دادهها را به روش های مختلفی غیر از مدلهای جدولی پیوسته سیستمهای مدیریت پایگاه داده رابطه ای (RDBMS) ذخیره و بازیابی میکند. این پایگاههای داده میتوانند انواع مختلفی از دادهها را مدیریت کنند و میتوانند انواع مدلهای داده از جمله ذخیرههای key-value، داکیومنت، ستونهای گسترده و گراف را در خود جای دهند.
مزایای استفاده از آنها برای کاربردهای مدرنی است که به مقیاس افقی سریع نیاز دارند و برای کسانی که مجموعه داده های توزیع شده بسیار بزرگ و سرعت بالایی دارند. راه حل های NoSQL DBaaS کاملا مدیریت شده برای موارد استفاده که در آن به تیمی از متخصصان برای مدیریت پیچیدگی و نگهداری چنین پایگاه های داده نیاز است، در حال افزایش است.
پایگاه های داده NoSQL برای چه مواردی استفاده می شود؟
بسیاری از انواع پایگاه داده NoSQL برای برنامه های کاربردی با مجموعه داده های بسیار بزرگ استفاده می شود و برخی در زمان واقعی کار می کنند. آنها توسط شرکتهایی استفاده میشوند که به ویژگیها و قابلیتهای انعطافپذیرتر از یک پایگاه داده سنتی نیاز دارند، که میتواند انواع مدلهای داده را در قالبهای مختلف (انعطاف پذیر) در خود جای دهد. یک برنامه پایگاه داده NoSQL ویژگی های مدیریت داده زیر را ارائه می دهد که در پایگاه داده های رابطه ای یافت نمی شوند:
- کشینگ- هنگامی که همان اطلاعات برای بسیاری از کاربران ارسال می شود، پاسخ برنامه را بهبود می بخشد. کش NoSQL دادهها راه حلی را بدون نیاز به نگهداری کش سفارشی ارائه میدهد.
- دادههای بسیار در دسترس و توزیعشده در سطح جهانی – با پایگاههای کاربر در سراسر جهان و الزامات سخت برای سرویسهای همیشه روشن، سیستمهای داده نمیتوانند فقط در یک مرکز داده داخلی واحد قرار گیرند. بسیاری از توزیع جهانی سرورها و تکثیر خودکار داده ها بین آنها پشتیبانی می کنند. به این کار Replication Cross Datacenter گفته می شود.
- دسترسی سریع به داده های بزرگ – نرم افزار NoSQL می تواند حجم عظیمی از داده ها را در سیستم های امروزی سریعتر و با هزینه کمتری نسبت به پایگاه داده های رابطه ای مدیریت کند. «سریع» اغلب به دو صورت قابل ارزیابی است: تأخیر، که سرعت زمانهای پاسخ را اندازهگیری میکند، که اغلب در محدوده میلیثانیه یا زیر میلیثانیه اندازهگیری میشود، و همچنین توان عملیاتی، که مقدار خام دادهای را که میتوان پردازش کرد، که اغلب بر حسب عملیات در ثانیه اندازهگیری میشود، اندازهگیری میکند.
- سازگاری – الزامات سازگاری بسیاری از موارد استفاده از پایگاههای داده NoSQL نسبت به پایگاههای داده رابطهای سختتر است. به عنوان مثال، هنگام مدیریت داده های زودگذر، گذرا و به سرعت در حال تغییر. در چنین مواردی، مقداری از دست دادن داده برای حفظ در دسترس بودن سیستم قابل قبول است. امروزه مدل ACID همیشه زمانی لازم نیست که یک مدل eventual consistency عملکرد بهتری را ارتقا دهد. برخی از آنها طیف وسیعی از سطوح سازگاری را برای انتخاب ارائه میدهند، از جمله tunable consistency,، که در آن هر تراکنش پایگاه داده ممکن است سطح سازگاری خاص خود را داشته باشد.
سرور مجازی یک ماشین مجازی کامل است که امکان تغییر در سیستم عامل آن برای کاربر فراهم میباشد.
خرید سرور مجازی در پنج موقعیت جغرافیایی ایران، ترکیه، هلند، آلمان و آمریکا با قابلیت تحویل آنی در پارسدو فراهم است.
ScyllaDB چیست؟
ScyllaDBیک پایگاه داده NoSQL توزیعشده و سازگار با Apache Cassandra است که برای ارائه عملکردی در سطح پایگاههای داده درونحافظهای (In-Memory) طراحی شده است. این پایگاه داده با استفاده از زبان برنامهنویسی C++ توسعه یافته و بهینهسازی شده تا عملکردی چند برابری نسبت به Cassandra ارائه دهد.
نحوه کار و معماری ScyllaDB
معماری ScyllaDB به گونهای طراحی شده که بتواند از سختافزارهای مدرن نهایت استفاده را ببرد. برخی از ویژگیهای کلیدی معماری این پایگاه داده عبارتند از:
۱. مدل پردازش غیرهمزمان
ScyllaDB از یک مدل پردازش اشتراک زمانی (Sharded Multi-Threaded Architecture) بهره میبرد که باعث میشود بار کاری به صورت مساوی بین هستههای پردازشی توزیع شود و از پردازندههای چندهستهای بهینهتر استفاده کند.
۲. بدون استفاده از Garbage Collection
برخلاف Cassandra که از زبان Java استفاده میکند و به ناچار تحت تاثیر Garbage Collection (GC) قرار میگیرد، ScyllaDB با بهرهگیری از C++ نیاز به GC ندارد که باعث کاهش تاخیر و بهبود عملکرد میشود.
۳. مدیریت حافظه کارآمد
ScyllaDB دارای یک مدیریت حافظه پویا و کارآمد است که امکان استفاده بهینه از RAM را فراهم میکند. این موضوع در پردازش دادههای حجیم تاثیر بسزایی دارد.
۴. مقیاسپذیری افقی واقعی
یکی از مهمترین مزایای ScyllaDB مقیاسپذیری افقی (Horizontal Scaling) است. این بدان معناست که بدون نیاز به تغییرات گسترده در زیرساخت، میتوان با افزودن گرههای جدید به کلاستر، ظرفیت پردازش و ذخیرهسازی را افزایش داد.
۵. سازگاری کامل با Cassandra API
این ویژگی به کاربران Cassandra امکان میدهد بدون نیاز به تغییرات زیاد در کدهای موجود، به ScyllaDB مهاجرت کنند.
مقایسه ScyllaDB با رقبا
ScyllaDB در مقایسه با سایر پایگاههای داده محبوب NoSQL مانند Apache Cassandra، MongoDB و Amazon DynamoDB، مزایا و معایب خاص خود را دارد.
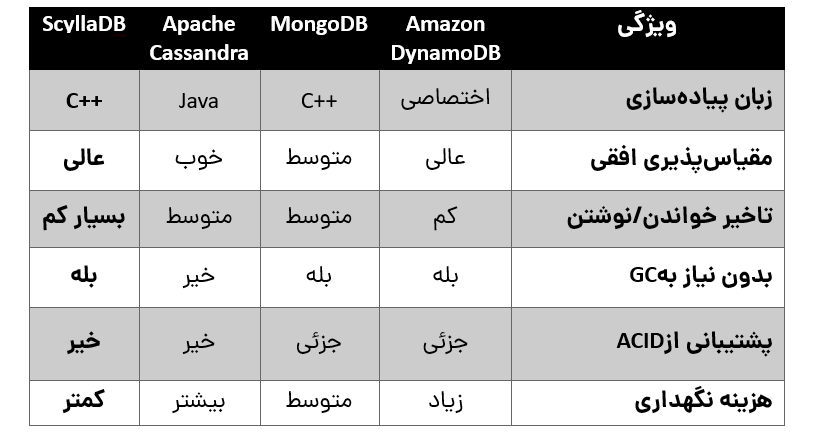
نتیجه: اگرچه Apache Cassandra به عنوان یک گزینه محبوب در بین پایگاههای داده توزیعشده شناخته میشود، اما ScyllaDB با عملکرد بهتر و هزینههای کمتر در نگهداری، گزینهای ایدهآل برای حجم بالای داده است. همچنین، در مقایسه با MongoDB، ScyllaDB برای پردازشهای تحلیلی سنگین و ذخیرهسازی توزیعشده عملکرد بهتری دارد.
چه کسانی باید از ScyllaDB استفاده کنند؟
- ScyllaDB گزینهای عالی برای سازمانها و شرکتهایی است که نیاز به ذخیرهسازی توزیعشده با کارایی بالا و تاخیر کم دارند. برخی از موارد استفاده شامل:
سرویسهای مالی و بانکی: به دلیل نیاز به پردازش سریع تراکنشها و قابلیت مقیاسپذیری بالا. - پلتفرمهای تبلیغاتی آنلاین: برای پردازش همزمان حجم بالای دادهها.
- سرویسهای استریم ویدیو: مانند Netflix و YouTube که به ذخیره و بازیابی سریع دادهها نیاز دارند.
- بازیهای آنلاین و چندنفره: که به پایگاه دادهای با تاخیر کم و ظرفیت بالا نیاز دارند.
- تحلیل کلانداده (Big Data Analytics): به دلیل نیاز به پردازش سریع حجم عظیمی از دادهها.
آموزش نصب ScyllaDB در لینوکس
برای نصب ScyllaDB در لینوکس به عنوان مثال Ubuntu 20.04 ، مراحل زیر را دنبال کنید:
۱. نصب مخزن ScyllaDB
curl -fsSL https://downloads.scylladb.com/deb/repo.key | sudo gpg --dearmor -o /usr/share/keyrings/scylla-keyring.gpg echo "deb [signed-by=/usr/share/keyrings/scylla-keyring.gpg] https://downloads.scylladb.com/deb/debian/ $(lsb_release -sc) main" | sudo tee /etc/apt/sources.list.d/scylla.list sudo apt update
۲. نصب ScyllaDB
sudo apt install -y scylla
۳. پیکربندی اولیه
پس از نصب، میتوانید پیکربندی اولیه را اجرا کنید:
sudo scylla_setup
این دستور شما را از طریق تنظیمات شبکه، ذخیرهسازی، و دیگر پیکربندیهای مهم راهنمایی میکند.
۴. راهاندازی سرویس ScyllaDB
sudo systemctl start scylla-server sudo systemctl enable scylla-server
۵. بررسی وضعیت سرویس
sudo systemctl status scylla-server
پس از انجام این مراحل، ScyllaDB شما آماده استفاده است و میتوانید با استفاده از cqlsh یا APIهای مربوطه با آن ارتباط برقرار کنید.
جمعبندی
ScyllaDB به عنوان یکی از سریعترین پایگاههای داده NoSQL توزیعشده، توانسته است جایگاه خود را در بین سازمانهایی که به مقیاسپذیری و کارایی بالا نیاز دارند، تثبیت کند. اگر به دنبال جایگزینی سریعتر، بهینهتر و کمهزینهتر برای Apache Cassandra هستید، ScyllaDB میتواند گزینهای فوقالعاده باشد.
اگر شما نیز تجربه استفاده از ScyllaDB را دارید، خوشحال میشویم دیدگاههای خود را با ما به اشتراک بگذارید!


