


مدیریت سرورهای فیزیکی در سازمانها و دیتاسنترها نیازمند نظارت دقیق بر سلامت سختافزار و رفتار عملیاتی سیستم است. در سرورهای HP، ابزار iLO نقش کلیدی در مانیتورینگ و مدیریت از راه دور ایفا میکند. یکی از هشدارهای رایج در این محیط، اخطار افزایش دما است، هشداری که میتواند ناشی از فشار عملیاتی، اختلال در سیستم خنککننده یا مشکل محیطی باشد و در صورت بیتوجهی، منجر به آسیب جدی سختافزار شود.
در این مطلب، اقدامات مهم و تخصصی که تیم DevOps در مواجهه با هشدارهای دما در iLO باید انجام دهد، بهصورت مرحلهبهمرحله بررسی میکنیم.
۱. تحلیل و تشخیص دقیق علت هشدار دما
اولین قدم در مواجهه با پیامهای دمای iLO، بررسی علل اصلی است. این ابزار اطلاعات کاملی درباره:
- وضعیت سنسورهای دما
- سرعت چرخش فنها
- ولتاژ و الگوی بار پردازشی
- تاریخچه خطاها و هشدارها
ارائه میدهد و تشخیص دقیق مشکل را آسانتر میکند.
تیم DevOps باید این دادهها را بررسی نموده و مشخص کند که افزایش دما بهدلیل یکی از عوامل زیر رخ داده است:
- دمای محیط رک یا دیتاسنتر
- خرابی یا کاهش عملکرد فنها
- انسداد گردش هوا بهعلت گرد و غبار
- افزایش بار پردازشی یا اجرای سرویسهای سنگین
برای تحلیل دقیقتر، ترکیب دادههای iLO با ابزارهای مانیتورینگ مانند Zabbix، Nagios یا Prometheus یک رویکرد حرفهای و استاندارد محسوب میشود.
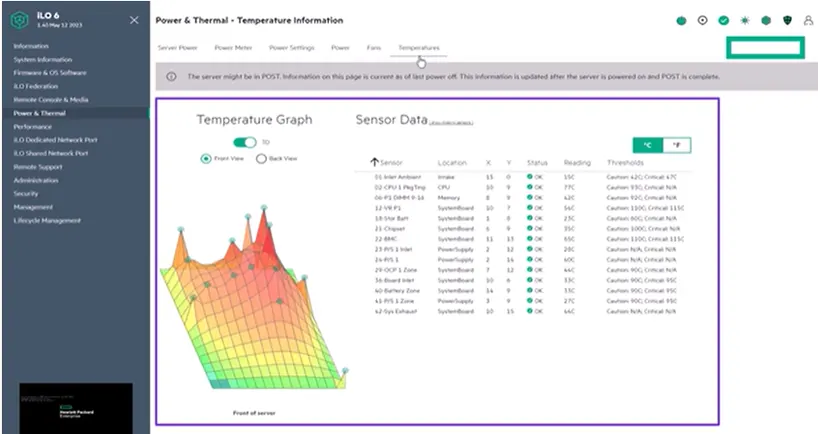
۲. اقدامات فوری برای جلوگیری از آسیب سختافزاری
در صورت مشاهده هشدار، اقدامات سریع و هدفمند ضروری است. تیم DevOps باید:
- کاهش موقت بار پردازشی یا انتقال سرویسها به نودهای دیگر
- خاموشکردن کنترلشده سرور در موارد بحرانی
- متوقفکردن سرویسهای غیرضروری
- بررسی لحظهای لاگها و وضعیت فنها
را انجام دهد تا حرارت سیستم کاهش یابد.
تصمیمگیری در این مرحله باید براساس SLA سازمان، درجه اهمیت سرویسها و معماری زیرساخت انجام شود.
۳. بررسی سیستم خنککننده و شرایط محیطی دیتاسنتر
یکی از رایجترین عوامل افزایش دما، اختلال در سیستم خنککننده است. در این مرحله لازم است:
- عملکرد فنها و سرعت گردش آنها کنترل شود
- سلامت هیتسینکها و تراکم گردوغبار بررسی گردد
- مسیر گردش هوا در رکها ارزیابی شود
- دمای محیط دیتاسنتر و عملکرد سیستمهای سرمایشی بررسی شود
جریان هوای نامناسب یا دمای بالای محیط میتواند مستقیم باعث افزایش دمای CPU، RAM و حتی کنترلرهای RAID شود. این موارد باید بهصورت روتین توسط تیم DevOps و تیم Facilities کنترل گردد.
۴. استفاده از امکانات iLO برای مدیریت بهینه دما
iLO امکانات گستردهای برای مدیریت دما و پیشگیری از بحران دارد. مهمترین قابلیتها عبارتند از:
- تنظیم Threshold برای هشدارهای دما
- فعالسازی هشدارهای Email، Syslog یا SNMP Trap
- بررسی Integrated Management Log (IML)
- مانیتورینگ لحظهای فنها و دما
با پیکربندی صحیح این تنظیمات میتوان هشدارها را قبل از رسیدن دما به آستانه بحرانی دریافت کرد و سریعتر وارد عمل شد.
۵. اقدامات پیشگیرانه برای جلوگیری از تکرار هشدار دما
مدیریت دما یک فرآیند یکباره نیست، بخشی از نگهداری پیشگیرانه (Preventive Maintenance) محسوب میشود. اقدامات کلیدی برای جلوگیری از بروز مجدد شامل موارد زیر است:
- تمیزکاری منظم رکها و سرورها
- بررسی و تعویض دورهای فنها و هیتسینکها
- بهینهسازی بار پردازشی و Load Balancing
- بهبود جریان هوای ورودی و خروجی رک
- مانیتورینگ ۲۴/۷ با ابزارهای DevOps
- ایجاد داشبوردهای هشداردهنده و تحلیل داده
این فرآیندهای روتین، نقش مهمی در حفظ سلامت سختافزار و افزایش طول عمر سرورها دارند.
برای پروژههای مهم خود به دنبال سرور مطمئن هستید؟ خرید سرور مجازی با IP ثابت و سرعت بالا در پارسدو، گزینهای ایدهآل است.
اهمیت هشدار دما
افزایش دما در سرورهای HP تنها یک خطای سیستمی نیست، بلکه زنگ خطری برای احتمال بروز آسیبهای جدی در پردازنده، ماژولهای RAM و کنترلرهای استوریج است. iLO با ارائه هشدارهای لحظهای، اولین لایه دفاعی در برابر این تهدید محسوب میشود و نادیدهگرفتن این پیامها میتواند هزینههای سنگین تعمیر یا حتی از دست دادن اطلاعات را در پی داشته باشد.
توضیح درباره Thresholdها و رفتار سیستم
یکی از مهمترین نکاتی که باید درباره هشدارهای دمایی iLO در نظر گرفت، وجود دو آستانه کلیدی یعنی Caution و Critical است. در سطح هشدار Caution، سیستم تلاش میکند با افزایش سرعت فنها، وضعیت را به حالت پایدار برگرداند و در صورت ادامهدار بودن افزایش دما، یک خاموشی نرم (Graceful Shutdown) برای جلوگیری از آسیب به سیستمعامل آغاز میشود. اما در آستانه Critical، آیلو برای جلوگیری از خرابیهای الکترونیکی و ذوبشدن قطعات، بهصورت فوری یا با یک تاخیر چندثانیهای، سرور را فیزیکی خاموش میکند. مدیریت حرارتی سرور یک فرآیند بسیار هوشمند و لایهمند است.
تشریح تفاوت سیاستهای مانیتورینگ
سیاستهای مانیتور دما در iLO بسته به نوع سرور، بارکاری و طراحی محیط عملیاتی متفاوت هستند. برخی سرورها در شرایط بار بالا سریعتر وارد فاز افزایش سرعت فن میشوند، در حالیکه برخی دیگر امکان تحمل دمای بیشتری دارند. تحلیل هشدار دما نباید فقط براساس اعداد خام باشد، بلکه باید نسبت به نیازهای واقعی سرویس و پیکربندی سختافزار نیز سنجیده شود.
اهمیت Logها و IML در پیگیری مشکلات
یکی از مواردی که معمولا نادیده گرفته میشود، نقش حیاتی IML در تشخیص ریشه مشکلات دمایی است. ثبت دقیق رخدادها در IML به تیم فنی این امکان را میدهد که رفتار دمایی سیستم را در بازه زمانی بررسی کرده و ارتباط آن را با ترافیک کاری، افت کارایی فنها یا مشکلات محیطی تحلیل کنند.
رفتار سیستم پس از رفع مشکل دما
iLO تنها در لحظه هشدار فعال نیست، بلکه پس از بازگشت دما به محدوده نرمال، مجموعهای از اقدامات اصلاحی را برای جلوگیری از پیامدهای بعدی انجام میدهد. این اقدامات شامل بازگرداندن سرعت فن به حالت عادی، ثبت رخداد در IML و خاموشکردن LEDهای هشدار است.
ارزش عملی برای DevOps و مدیریت زیرساخت
برای تیمهای DevOps، درک این مکانیسمها فقط یک دانش فنی نیست، بلکه ابزار تصمیمگیری برای مدیریت ظرفیت، برنامهریزی خنککننده و پیشگیری از داونتایم است.
جمعبندی
هشدار افزایش دما در iLO یک نشانه حیاتی و جدی است که نباید نادیده گرفته شود. واکنش سریع و تخصصی تیم DevOps، از تشخیص دقیق علت و انجام اقدامات فوری گرفته تا بررسی سیستم خنککننده، بهرهگیری از قابلیتهای مدیریتی iLO و اجرای برنامههای پیشگیرانه، نقش تعیینکنندهای در جلوگیری از آسیبهای سختافزاری و کاهش ریسک توقف سرویسها دارد. مدیریت صحیح این هشدارها نهتنها از بروز اختلالات جدی جلوگیری میکند، بلکه یکی از مهمترین عوامل پایداری، عملکرد بهینه و سلامت بلندمدت زیرساختهای سازمانی محسوب میشود.


