


در این مطلب، سناریوی تقسیم مغزی (Split Brain) را با مثالهای عملی دنیای واقعی بررسی خواهیم کرد و به مفاهیم حد نصاب (quorum ) و یک مثال عملی از چگونگی جلوگیری etcd از سناریوی split brain با استفاده از الگوریتم اجماع Raft خواهیم پرداخت.
هر زمان که سیستمهای توزیعشدهای (distributed systems) را که با دادهها سروکار دارند، مستقر میکنیم، معمولا گرهها را در مناطق دسترسی مختلف یا مراکز داده مختلف (برای محیطهای on-prem) مستقر میکنیم تا از در دسترس بودن بالا اطمینان حاصل شود.
مثال: دیتابیسی مانند MongoDB، سیستمهای ذخیرهسازی توزیعشده مانند GlusterFS و کلاسترهای مبتنی بر اجماع مانند etcd.
بیایید مثالی از یک کلاستر etcd را در نظر بگیریم؛ فرض کنید یک کلاستر etcd با ۵ گره داریم. برای حفظ دسترسیپذیری بالا، سه گره در Zone 1 مستقر میشوند، در حالی که دو گره باقیمانده در Zone 2 قرار میگیرند.
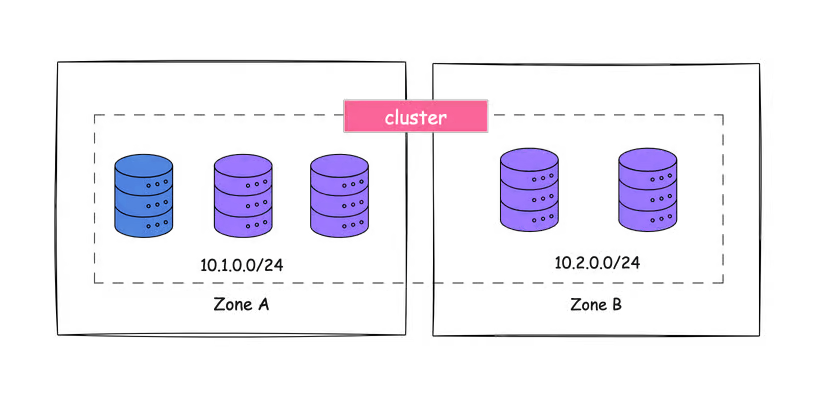
این تنظیمات تضمین میکند که حتی اگر یک منطقه از کار بیفتد، هنوز گرههای فعال در منطقه دیگر وجود دارند و تداوم سرویس را حفظ میکنند.
سناریوی تقسیم مغزی (Split Brain) در سیستمهای توزیعشده
در سیستمهای توزیعشده، سناریوی Split-Brain زمانی رخ میدهد که گروهی از گرهها ارتباط خود را با یکدیگر از دست میدهند، که معمولا به دلیل پارتیشنبندی شبکه است.
به عنوان مثال، در کلاستر etcd با ۵ گره ما، اگر اتصال شبکه بین Zone 1 و Zone 2 قطع شود، سه گره در Zone 1 ممکن است به کار خود ادامه دهند و یک حد نصاب اکثریت تشکیل (majority quorum) دهند.
با این حال، دو گره در Zone 2 ممکن است فرض کنند که باید به طور مستقل به کار خود ادامه دهند و یک کلاستر دوم و متناقض (conflicting cluster) ایجاد کنند.
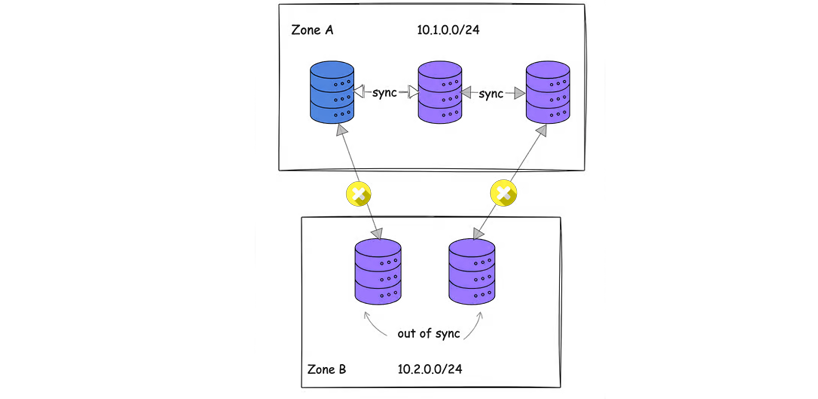
این منجر به مشکل کلاسیک Split-Brain میشود، که در آن:
- برخی از گرهها به کار خود ادامه میدهند و دادههای جدید را میپذیرند. گرههای دیگر، که از اکثریت جدا شدهاند، نیز به کار خود ادامه میدهند، اما نمیدانند طرف مقابل چه کاری انجام میدهد.
- از آنجایی که هر دو طرف دادههای جدید را جداگانه مینویسند، دیگر با هم مطابقت ندارند.
- وقتی مشکل شبکه برطرف شود، این گرهها ممکن است برای رسیدن به هم تلاش کنند که منجر به دادههای اشتباه یا از دست رفته میشود.
حد نصاب در سیستمهای توزیعشده
برای جلوگیری از سناریوهای Split-Brain، سیستمهای توزیعشده از تصمیمگیری مبتنی بر حد نصاب (quorum-based) برای اطمینان از سازگاری استفاده میکنند.
بیایید مفهوم حد نصاب را با مثالهایی درک کنیم.
هنگامی که کلاسترهای دیتابیس را مستقر میکنید، دو الگوی کلیدی وجود دارد:
- گره Single-Primary: همه نوشتنها به گره اصلی میروند که سپس آن تغییرات را به گرههای ثانویه تکرار (replicate) میکند.
- گره Multi-Primary: در این تنظیمات، چندین گره میتوانند نوشتنها را همزمان بپذیرند. وقتی در هر گره اصلی مینویسید، آن گره با دیگران هماهنگ میشود تا از تکرار صحیح نوشتن اطمینان حاصل شود.
بنابراین چگونه گره اصلی را انتخاب کنیم؟
بیشتر دیتابیسهای توزیعشده از مکانیسم انتخاب رهبر (leader election) برای تعیین گره اصلی استفاده میکنند. یک مثال کلاسیک، الگوریتم اجماع Raft در etcd است.
مانند یک فرآیند رایگیری عمل میکند و برای انتخاب یک رهبر، یک گره کاندید باید اکثریت آرا را دریافت کند.
برای مثال، در یک سیستم ۵ گرهای، حداقل ۳ گره باید قبل از هرگونه تصمیمگیری به توافق برسند. این گروه اکثریت، حد نصاب (quorum) نامیده میشود.
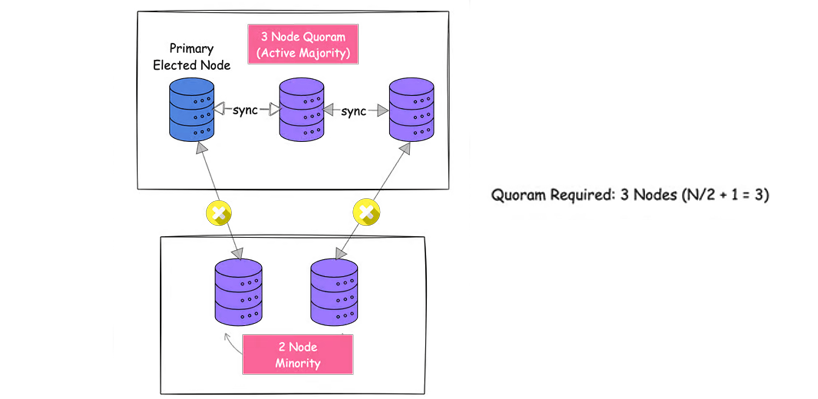
حد نصاب معمولا به صورت (N/2 + 1) محاسبه میشود که در آن N تعداد کل گرههای سیستم شماست. این تضمین میکند که شما همیشه اکثریت را داشته باشید.
به عنوان مثال:
- در یک سیستم ۵ گرهای، برای تشکیل حد نصاب به ۳ گره نیاز دارید (۵/۲ + ۱ = ۳)
- در یک سیستم ۷ گرهای، به ۴ گره نیاز دارید (۷/۲ + ۱ = ۴)
به همین دلیل است که کلاستر معمولا با تعداد فرد سرور، از ۳ شروع میشوند، تا اطمینان حاصل شود که همیشه میتوان اکثریت (حد نصاب) را تشکیل داد.
سناریوی دنیای واقعی (etcd)
طبق مستندات رسمی etcd، از سناریوهای split-brain در etcd به طور موثر اجتناب میشود.
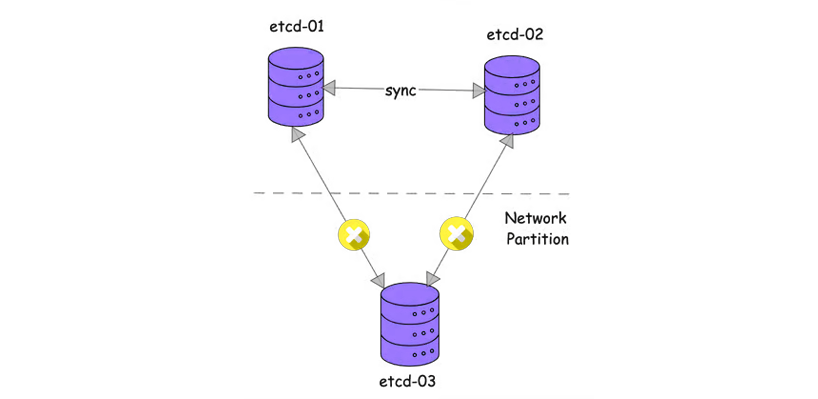
نحوه انجام کار به این صورت است:
- هنگامی که یک پارتیشن شبکه رخ میدهد، کلاستر etcd به دو بخش تقسیم میشود: اکثریت و اقلیت.
- بخش اکثریت به عنوان کلاستر موجود به کار خود ادامه میدهد، در حالی که بخش اقلیت از دسترس خارج میشود.
- اگر رهبر در بخش اکثریت قرار داشته باشد، سیستم این خرابی را به عنوان خرابی پیرو اقلیت در نظر میگیرد. بخش اکثریت بدون هیچ تاثیری بر سازگاری، عملیاتی باقی میماند.
- اگر رهبر بخشی از بخش اقلیت باشد، تشخیص میدهد که به دلیل از دست دادن ارتباط با اکثریت گرههای کلاستر، جدا شده است و از نقش رهبری خود کنارهگیری میکند.
- سپس بخش اکثریت یک رهبر جدید انتخاب میکند و دسترسی و سازگاری مداوم را تضمین میکند.
- پس از حل شدن پارتیشن شبکه، بخش اقلیت به طور خودکار رهبر جدید را از بخش اکثریت شناسایی کرده و وضعیت خود را بر اساس آن همگامسازی میکند.
برای پروژههای مهم خود به دنبال سرور مطمئن هستید؟ خرید سرور مجازی با IP ثابت و سرعت بالا در پارسدو، گزینهای ایدهآل است.
این طراحی تضمین میکند که etcd حتی در مواجهه با مشکلات شبکه، سازگاری قوی را حفظ کرده و از سناریوهای split-brain جلوگیری میکند.
ممکن است بپرسید، etcd چگونه در طول پارتیشن شبکه تعیین میکند که یک گره در اکثریت است یا اقلیت؟
هر گره etcd تعداد کل گرههای موجود در کلاستر را به عنوان بخشی از پیکربندی خود میداند. این تعداد در لیست عضویت etcd ذخیره میشود که موارد زیر را دنبال میکند:
- اندازه کل کلاستر (N)
- شناسهها و آدرسهای گره
- رهبر فعلی (در صورت انتخاب)
گرهها مدام پیامهایی (heartbeats) ارسال میکنند تا تایید کنند که کدام گرهها هنوز قابل دسترسی هستند. پس از تشخیص یک پارتیشن، هر گره بررسی میکند که با چند گره دیگر هنوز میتواند صحبت کند.
این عدد را با نیاز به حد نصاب (N/2 + 1) مقایسه میکند. اگر یک گره هنوز بتواند با حداقل حد نصاب (N/2 + 1) گره ارتباط برقرار کند، میداند که در اکثریت است. اگر نتواند به حد نصاب برسد، متوجه میشود که در اقلیت است و تصمیمگیری را متوقف میکند.
نتیجهگیری
برای مهندسان DevOps، درک سناریوهای تقسیم مغزی (Split Brain) برای حفظ سیستمهای توزیعشده قابل اعتماد مهم است. از آنجایی که برنامههای مدرن به دیتابیسهای توزیعشده، سیستمهای ذخیرهسازی و کلاسترهای مبتنی بر اجماع متکی هستند، مدیریت موثر پارتیشنهای شبکه و خرابیهای حد نصاب ضروری است.
تیمهای DevOps باید به طور پیشگیرانه استراتژیهایی را برای جلوگیری از Split-Brain پیادهسازی کنند، از ثبات دادهها، در دسترس بودن و انعطافپذیری کلی سیستم اطمینان حاصل کنند.


