


هدوپ (Hadoop) یک فریمورک متنباز است که به پردازش و ذخیره مقادیر زیادی داده در چندین کامپیوتر کمک میکند. با توزیع حجم کار، دادههای گسترده و بدون ساختار را به طور موثر مدیریت کرده و آن را برای تجزیه و تحلیل دادههای بزرگ و اپلیکیشنهای وب در مقیاس بزرگ ایده آل مینماید.Hadoop ابزاری مناسب برای سازمانهایی است که به دنبال مدیریت آسان دادههای پیچیده هستند.
پیش نیازهای نصب Apache Hadoop در ویندوز
برای نصب Hadoop در ویندوز، دستگاه شما باید تمام مشخصات زیر را داشته باشد:
- ۸ گیگابایت رم ایده آل است؛ اگر SSD دارید، حتی ۴ گیگابایت هم میتواند کار کند.
- یک CPU چهار هستهای (۱.۸۰ گیگاهرتز یا سریعتر) برای عملکرد روان توصیه میشود.
- Java Runtime Environment (JRE) 1.8: مطمئن شوید که نصب کننده آفلاین را دانلود کردهاید.
- Java Development Kit (JDK) 1.8
- ابزار Unzipping (از ۷-Zip یا WinRAR استفاده کنید)
- Hadoop Zip: این آموزش از نسخه ۲.۹.۲ استفاده می کند، اما می توانید هر نسخه پایدار را از وب سایت رسمی Hadoop انتخاب کنید.)
راهنمای کامل نصب Hadoop در ویندوز
قبل از پرداختن به مراحل نصب Hadoop در ویندوز، مطمئن شوید که سیستم شما به درستی آماده شده است. این مطلب شما را در فرآیند راه اندازی راهنمایی میکند تا هدوپ را برای کارهای بیگ دیتا راه اندازی و اجرا کنید.
اگر ترجیح میدهید از یک ویپی اس برای انجام وظایف بیگ دیتا از راه دور و برای انعطاف پذیری بیشتر استفاده کنید، یک سرور مجازی ویندوز قابل اعتماد میتواند تجربه شما را ساده کند.
مرحله ۱: Hadoop را از حالت فشرده خارج نموده و نصب کنید
پس از دانلود Hadoop، اولین کار باز کردن فایلها از حالت فشرده است.
فایل hadoop-3.4.1.tar.gz را اکستراکت کنید تا پوشه Hadoop را در اختیار شما بگذارد.
برای منظم نگه داشتن موارد، به شما توصیه میکنیم پوشهای ایجاد کنید که در آن Hadoop را ذخیره کنید.
توجه: مطمئن شوید که در نام پوشهها از فاصله استفاده نکنید، زیرا ممکن است بعدا مشکلاتی ایجاد کند.
مرحله ۲: تنظیم متغیرهای محیطی
این مرحله برای اطمینان از اینکه سیستم شما مکان نصب جاوا و هدوپ را تشخیص دهد بسیار مهم است.
برای این کار مسیر زیر را دنبال کنید:
نوار جستجو را در ویندوز باز و Environment Variables را تایپ نمائید تا تنظیمات را به راحتی پیدا کنید.
پس از ورود، روی New در زیر User Variables کلیک کنید.
JAVA_HOME را به عنوان نام متغیر وارد کرده و برای مقدار متغیر، مسیر را در پوشه JDK خود قرار دهید. برای ذخیره OK را فشار دهید.
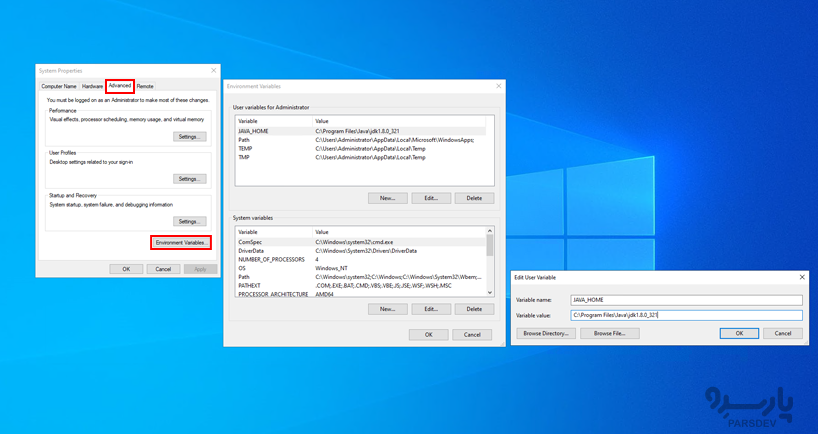
- درست مانند جاوا، HADOOP_HOME را تنظیم کنید. یک متغیر جدید ایجاد و مسیر دایرکتوری Hadoop خود را تنظیم کنید.
- در نهایت، Path متغیر سیستم را ویرایش کنید تا بداند دستورات جاوا و هدوپ را کجا پیدا کند.
- روی Path و سپس Edit کلیک کنید و سه خط زیر را یکی یکی اضافه نمائید:
%JAVA_HOME%\bin %HADOOP_HOME%\bin %HADOOP_HOME%\sbin
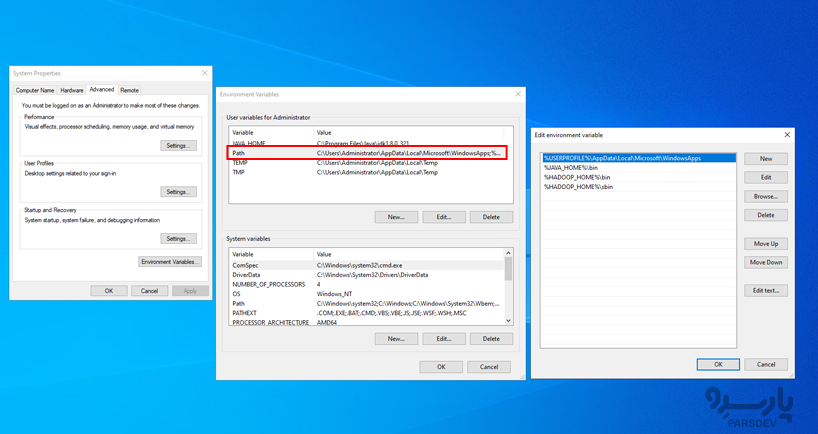
پس از افزودن این مسیرها، OK را بزنید، و پیکربندی متغیرهای محیطی تمام شده است.
مرحله ۳: بررسی متغیرهای محیطی
قبل از ادامه، مطمئن شوید همه چیز به درستی تنظیم شده است. یک خط فرمان جدید باز و دستورات زیر را اجرا کنید:
echo %JAVA_HOME% echo %HADOOP_HOME% echo %PATH%
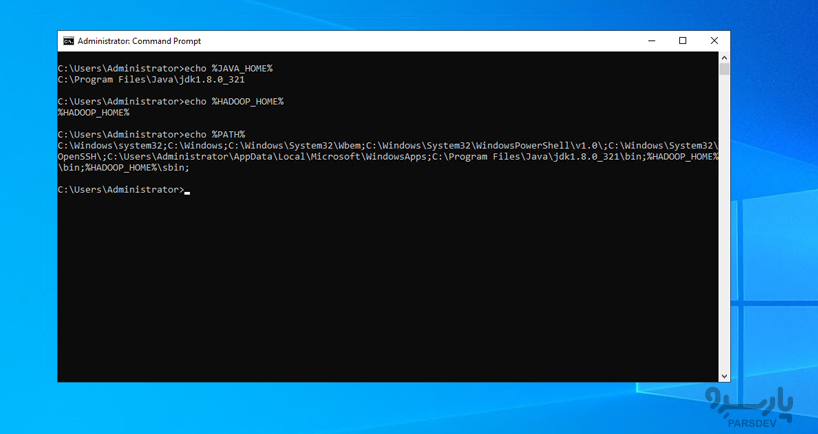
اگر هر دو دستور مسیرهای صحیح را برگردانند، همه چیر مرتب است!
مرحله ۴: پیکربندی Hadoop
اکنون، شما آماده پیکربندی خود Hadoop هستید. این بخش شامل ایجاد پوشههای لازم و ویرایش چند فایل پیکربندی است:
در پوشه Hadoop خود، یک پوشه جدید به نام data ایجاد کنید. در این پوشه data، دو زیرپوشه namenode و datanode را ایجاد نمائید. اینها دادههای فایل سیستم Hadoop را ذخیره میکنند. NameNode متادیتا را مدیریت نموده و DataNode بلوکهای داده واقعی را ذخیره مینماید.
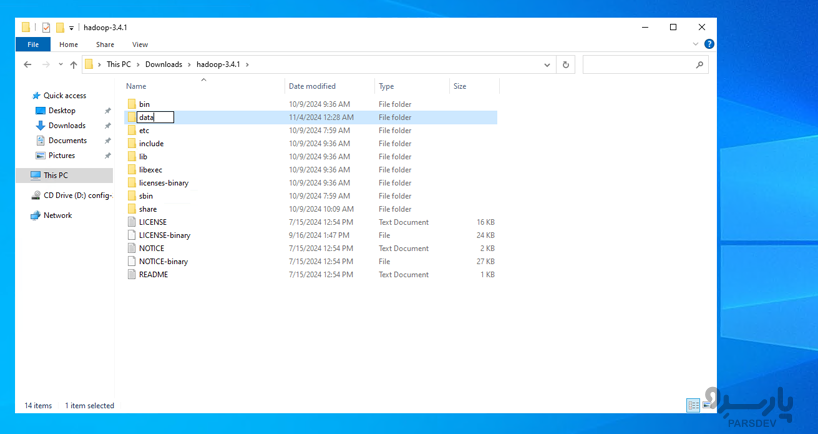
برای نمونه به D:\Hadoop\etc\hadoop بروید و این مراحل را برای ویرایش فایلهای Configuration دنبال کنید.
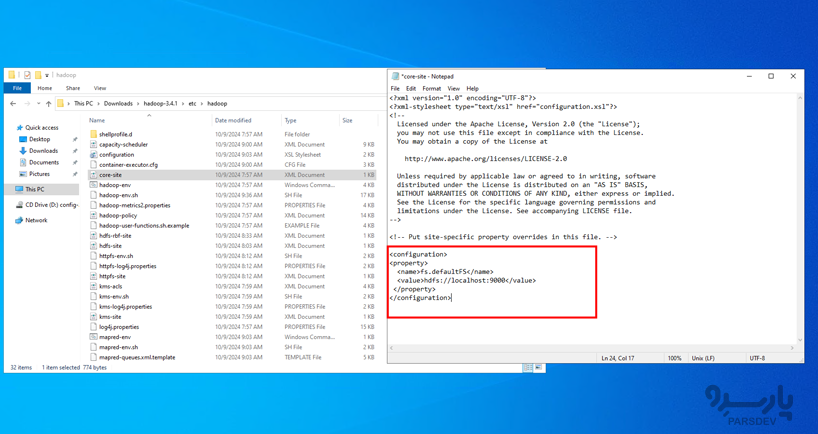
فایل زیر به Hadoop میگوید که فایل سیستم پیشفرض کجاست:
* core-site.xml * hdfs-site.xml * mapred-site.xml * yarn-site.xml * hadoop-env.cmd
برای ویرایش core-site.xml، آن را در یک ویرایشگر متن، باز و کد زیر را بین تگهای configuration اضافه کنید:
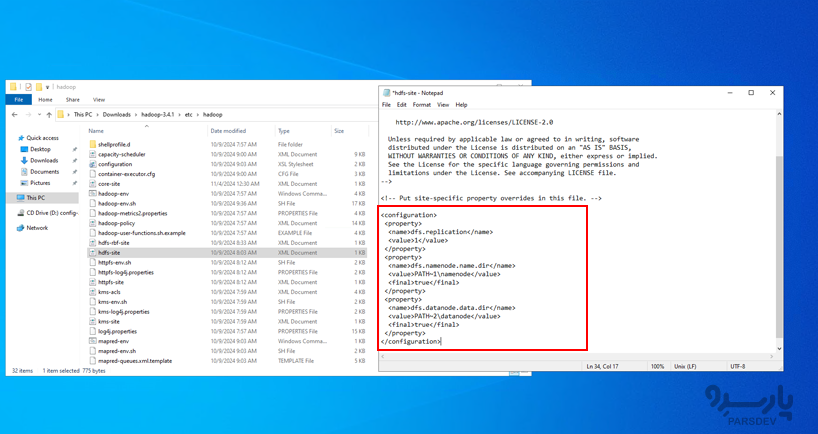
ویرایش hdfs-site.xml مکانهای ذخیره سازی NameNode و DataNode Hadoop را پیکربندی میکند:
برای پیکربندی MapReduce، این را به فایل اضافه کنید:
mapreduce.framework.name yarn
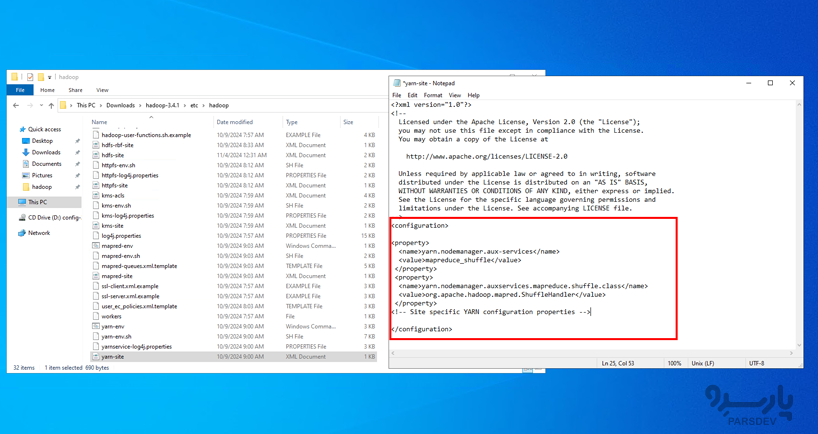
YARN مدیر منابع هدوپ (Hadoop) است. برای ویرایش yarn-site.xml، خطوط زیر را اضافه کنید:
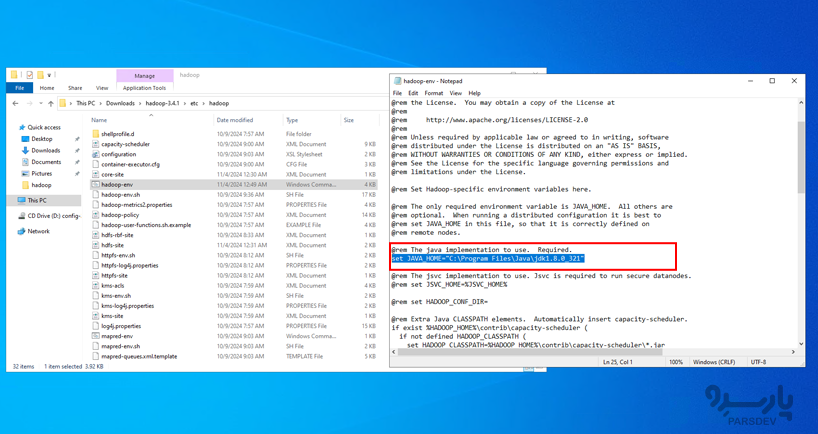
در نهایت، hadoop-env.cmd را ویرایش خواهید کرد. بررسی کنید که مسیر JAVA_HOME به درستی در hadoop-env.cmd تنظیم شده باشد. در صورت نیاز، خط پیش فرض را با:
set JAVA_HOME=%JAVA_HOME%
یا
set JAVA_HOME="C:\Program Files\Java\jdk1.8.0_221"
مرحله ۵: پوشه Bin را جایگزین کنید
پوشه bin پیشفرض Hadoop ممکن است در برخی از نسخهها به راحتی در ویندوز کار نکند، بنابراین بهتر است آن را با یک پوشه از پیش پیکربندی شده جایگزین کنید.
برای جایگزینی پوشه bin برای Hadoop در ویندوز، باید فایلهای لازم را دانلود کنید. میتوانید پوشه bin از پیش پیکربندی شده برای نسخه مورد نظر خود را مستقیم از مخزن GitHub دریافت کنید.
برای سازگاری بهتر با ویندوز، فایلها را دانلود و اکستراکت کنید تا جایگزین فایلهای موجود در دایرکتوری Hadoop شود.
مرحله ۶: تست تنظیمات
اکنون زمان آن است که آزمایش کنید آیا همه چیز به درستی تنظیم شده است یا خیر:
- NameNode را فرمت کنید
در یک خط فرمان جدید، اجرا کنید:
hadoop namenode -format
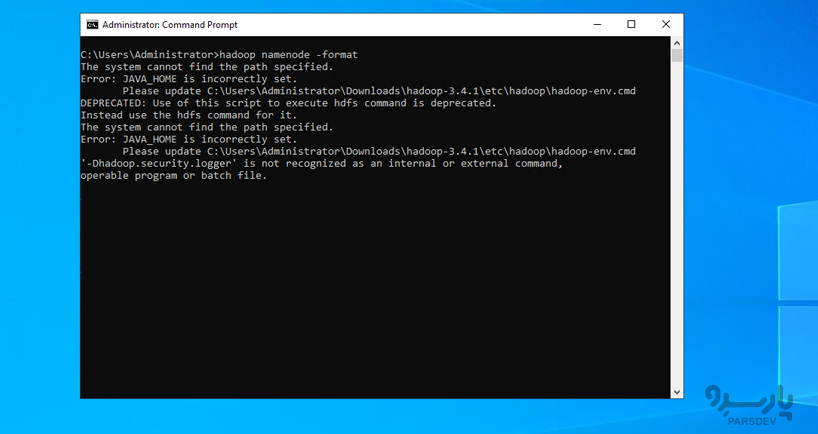
سیستم ذخیره سازی NameNode را مقداردهی اولیه میکند. به یاد داشته باشید، این دستور فقط برای بار اول ضروری است.
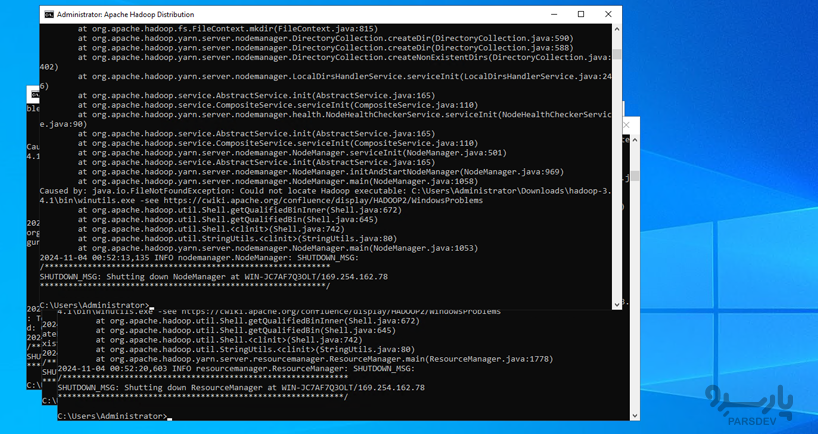
- سرویس Hadoop را استارت کنید
برای راه اندازی Hadoop، دستور زیر را اجرا کنید:
start-all.cmd
با این کار چندین پنجره فرمان باز میشود که نشان میدهد دیمنهای مختلف Hadoop در حال اجرا هستند، مانند NameNode، DataNode، ResourceManager و NodeManager.
مرحله ۷: تایید نصب
پس از تکمیل پنجره نصب Hadoop، میتوانید بررسی کنید که آیا Hadoop فعال است یا خیر، مرورگر خود را باز کنید و از این URL ها دیدن کنید:
- NameNode:
https://localhost:50070– این صفحه سلامت NameNode شما را نشان می دهد.
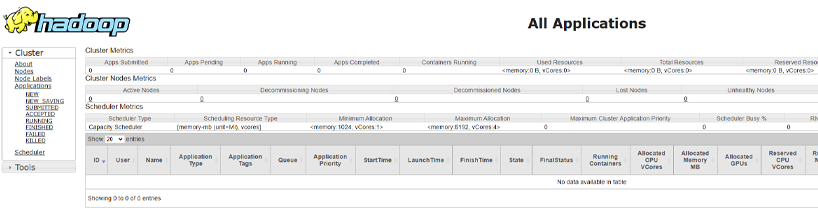
- ResourceManager:
https://localhost:8088 – در اینجا میتوانید میزان استفاده از منابع و اطلاعات شغلی را مشاهده کنید.
- Datanode:
https://localhost:50075 – برای تایید ذخیره سازی داده ها، این آدرس را در برگه مرورگر خود باز کنید.
سرور مجازی ویندوز یک ماشین مجازی کامل است که امکان دسترسی ریموت دسکتاپ از طریق RDP روی آن فراهم میباشد.
خرید سرور مجازی در پنج موقعیت جغرافیایی ایران، ترکیه، هلند، آلمان و آمریکا با قابلیت تحویل آنی در پارسدو فراهم است.
آیا می توانم هدوپ (Hadoop)را روی ویندوز ۱۰ نصب کنم؟
بله، نصب Hadoop در ویندوز ۱۰ با دانلود باینری هادوپ، تنظیم متغیرهای محیطی، پیکربندی فایل های XML و جایگزینی پوشه bin با نسخه سازگار با ویندوز امکان پذیر است.
چرا Hadoop بعد از نصب در ویندوز کار نمی کند؟
اگر Hadoop بعد از نصب کار نمیکند، ممکن است به دلیل پیکربندی نامناسب متغیرهای محیط، گم شدن یا نادرست بودن مسیرها در فایلهای core-site.xml و hdfs-site.xml، یا نسخه قدیمی پوشه bin باشد.
برای حل این مشکل، مطمئن شوید که مسیرها را به درستی تنظیم کرده اید و پوشه bin را با یک نسخه سازگار با ویندوز جایگزین کرده اید.
چگونه می توان Hadoop is not recognized as an internal or external command را برطرف کرد؟
این خطا به این معنی است که متغیرهای محیط شما به درستی تنظیم نشده اند.
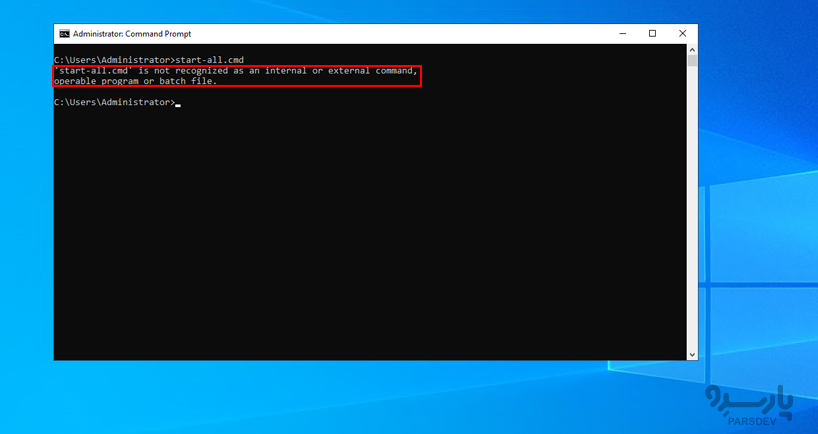
برای عیب یابی این خطا، مطمئن شوید که مسیرهای %JAVA_HOME%\bin، %HADOOP_HOME%\bin و %HADOOP_HOME%\sbin به PATH سیستم اضافه شده اند.
همچنین، با اجرای echo %JAVA_HOME% و echo %HADOOP_HOME% در یک خط فرمان جدید، تنظیمات را تایید کنید.
نتیجه گیری
این مطلب یک فرآیند گام به گام برای راه اندازی و نصب هدوپ (Hadoop) در سرور مجازی ویندوز است، از باز کردن فایلها و پیکربندی متغیرهای محیطی تا ویرایش فایلهای پیکربندی ضروری Hadoop را در آن بررسی کردیم. پس از تکمیل فرآیند نصب هدوپ در ویندوز و اجرای Hadoop، میتوانید با آپلود دادهها، اجرای کارهای MapReduce یا کاوش در YARN برای مدیریت منابع، کار با آن را شروع کنید.


